# Table {#sec-table} ## PKG ```{r} library (tidyverse) # 数据处理和可视化 library (gt) # 表格 library (gtsummary) # 表格 library (gtExtras) # gt 扩展 library (htmltools) # HTML 工具 # install.packages('cardx') library (survival) # 生存分析 library (knitr) # 表格 library (kableExtra) # kable 拓展 library (DT) # 交互式表格 library (reactable) # 交互式表格 library (formattable) # 交互式表格 library (flextable) # Word/PPT 表格 library (rhandsontable) # 交互式编辑表格 library (modelsummary) # 模型摘要表格 library (huxtable) # LaTeX 表格 ``` `Quarto` 无法正确加载,所有包装了函数,也放在了 wordcloud文件夹内: ```{r} # 因为有的交互式表格,无法正确加载,所有包装了函数,也放在了 wordcloud文件夹内 # 用法是embed_widget()包装一下,记得区块要写label <- function (widget, height = "400px" , width = "100%" ) {# 步骤 1: 生成一个基于当前代码块标签的、独一无二的文件名 # 这样可以防止多个小部件相互覆盖文件 <- opts_current$ get ('label' )<- paste0 ("./wordcloud/wc-" , chunk_label, ".html" )# 步骤 2: 将小部件保存为一个独立的、自包含的HTML文件 library (htmlwidgets)saveWidget (widget, filename, selfcontained = TRUE )# 步骤 3: 创建并返回一个指向该文件的 iframe HTML 标签 $ iframe (src = filename,height = height,width = width,style = "border:none;" ``` `R` 的表格包有很多, 主要分为以下几类: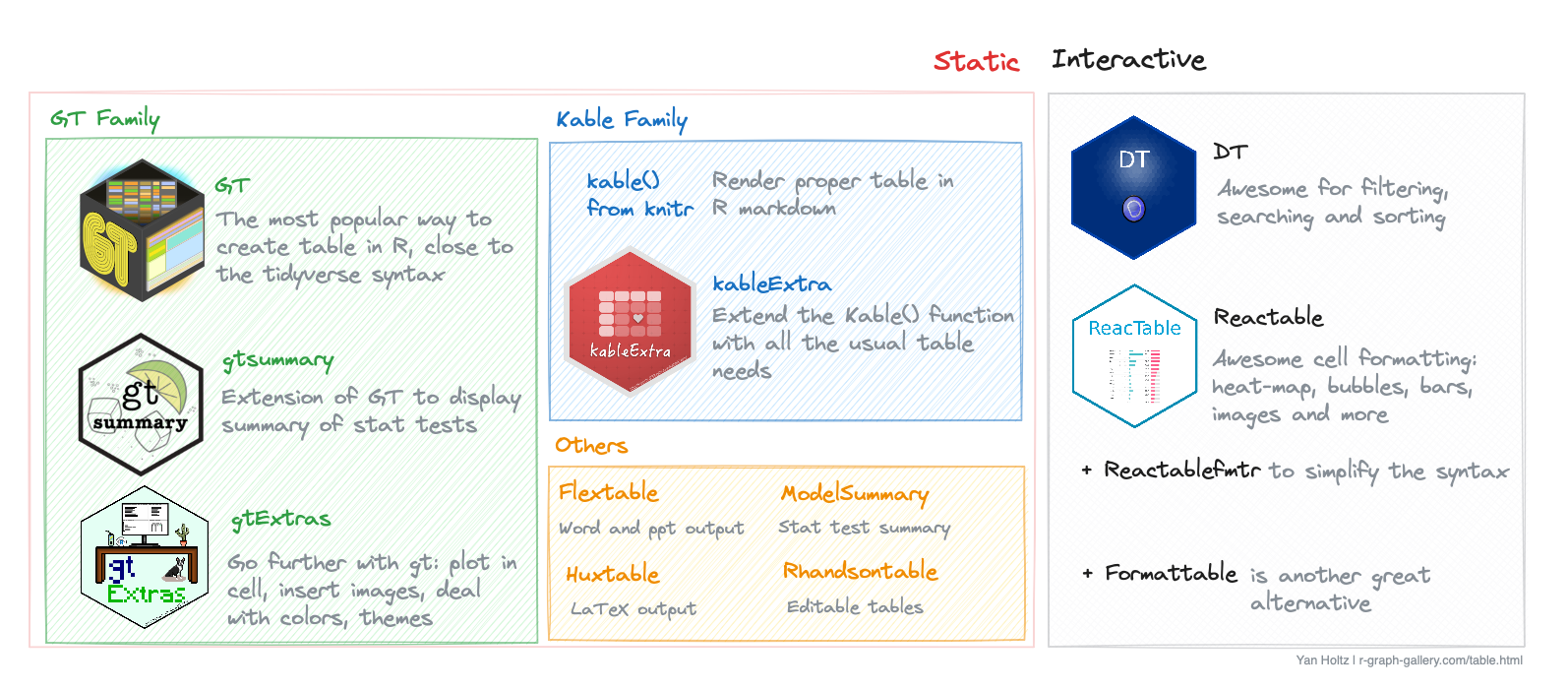 ## `gt family` `gt` 、`gtsummary` 和 `gtExtras` .### `gt` `gt` ([ 官方文档 ](https://gt.rstudio.com/) ) 是兼容 tidyverse 的表格包: #### 基本 ```{r} #| fig-cap: "使用 gt 包创建表格" # 创建一个简单的数据框 = data.frame (Country = c ("USA" , "China" , "India" , "Brazil" ), # 国家名称 Capitals = c ("Washington D.C." , "Beijing" , "New Delhi" , "Brasília" ), # 首都 Population = c (331 , 1441 , 1393 , 212 ), # 人口(百万) GDP = c (21.43 , 14.34 , 2.87 , 1.49 ) # GDP(万亿美元) gt (data)``` #### 标题 `tab_header()` 函数可以添加标题和副标题(兼容markdown / html语法):```{r} #| fig-cap: "使用 gt 包创建表格并添加标题和副标题(markdown 语法)" |> gt () |> tab_header (title = html ("<span style='color:red;'>A red title</span>" ), # 使用 html 语法 subtitle = md ("Pretty *cool subtitle* too, `isn't it?`" ) # 使用 markdown 语法 ``` ```{r} #| fig-cap: "使用 gt 包创建表格并添加图像作为标题" |> gt () |> tab_header (title = md ("**A table with an image as title**" ),subtitle = html ("<div style='text-align:center;'><img src='./image/Rlogo.png' height='60'></div>" ``` #### 跨列标题 `tab_spanner()` 函数可以创建跨列的标题(合并单元格):```{r} #| fig-cap: "使用 gt 包创建表格并添加跨列标题" |> gt () |> tab_spanner (label = "Number" ,columns = c (GDP, Population)) |> tab_spanner (label = "Label" ,columns = c (Country, Capitals)``` #### 脚注 `tab_footnote()` 函数的 `footnote` 和 `locations` 参数添加引用:```{r} #| fig-cap: "使用 gt 包为表格添加脚注" # 创建一个包含行星信息的数据框 = data.frame (Planet = c ("Earth" , "Mars" , "Jupiter" , "Venus" ), # 行星名称 Moons = c (1 , 2 , 79 , 0 ), # 卫星数量 Distance_from_Sun = c (149.6 , 227.9 , 778.3 , 108.2 ), # 距离太阳距离(百万公里) Diameter = c (12742 , 6779 , 139822 , 12104 ) # 直径(公里) |> gt () |> tab_footnote (footnote = md ("Measured in **millions** of Km" ),locations = cells_column_labels (columns = Distance_from_Sun)``` ```{r} #| fig-cap: "使用 gt 包为表格添加多个脚注" # 使用 gt 包创建表格,并为不同的列和表格整体添加多个脚注 |> gt () |> tab_footnote (footnote = md ("Measured in **millions** of Km" ), # 为 Distance_from_Sun 列添加脚注 locations = cells_column_labels (columns = Distance_from_Sun)|> tab_footnote (footnote = md ("Measured in **Km**" ), # 为 Diameter 列添加脚注 locations = cells_column_labels (columns = Diameter)|> tab_footnote (footnote = md ("The original data are from *Some Organization*" ) # 为整个表格添加脚注 |> opt_footnote_marks (marks = "LETTERS" ) # 设置脚注标记为大写字母 ``` ### `gtsummary` `gtsummary` 是 `gt` 的一个扩展包, 主要用于创建统计摘要表格.#### 回归模型摘要 `tbl_regression()` 函数可以创建回归模型的摘要表格:```{r} #| fig-cap: "使用 `tbl_regression()` 创建回归模型摘要表格" # 示例数据 data ("Titanic" )= as.data.frame (Titanic)# 建立logistics回归模型 = glm (Survived ~ Age + Class + Sex + Freq, family = binomial, data = df)# 使用 gtsummary 包创建表格 |> tbl_regression ()``` ```{r} #| fig-cap: "使用 `tbl_regression()` 创建回归模型摘要表格并增加统计量" |> tbl_regression (intercept = TRUE , conf.level = 0.9 ) |> # 增加截距和置信区间 add_glance_source_note () |> # 添加模型摘要信息 add_global_p () ``` #### 多模型合并 ```{r} #| fig-cap: "使用 `tbl_merge()` 合并多个模型的回归结果表格" data (trial)<- glm (response ~ trt + grade, data = trial, family = binomial) |> tbl_regression ()<- coxph (Surv (ttdeath, death) ~ trt + grade, data = trial) |> tbl_regression ()tbl_merge (list (model_reglog, model_cox),tab_spanner = c ("**Tumor Response**" , "**Time to Death**" )``` ### `gtExtras` `gtExtras` 增强并扩展了 `gt` 包的功能。可以创建更复杂和美观的表格。#### 汇总原始数据 `grouped by` , 制作 “每个单元格有很多数据” 的表格```{r} #| fig-cap: "结合 `grouped by`, 制作“每个单元格有很多数据”的表格" data (iris)# 创建一个包含鸢尾花数据的数据框 = iris |> group_by (Species) |> summarize (Sepal.L = list (Sepal.Length),Sepal.W = list (Sepal.Width),Petal.L = list (Petal.Length),Petal.W = list (Petal.Width)# 使用 gtExtras 包创建表格 |> gt ()``` #### 折线图 `gt_plt_sparkline()` 在表格单元格中创建折线图。`agg_iris` 汇总数据框:```{r} #| fig-cap: "使用 `gt_plt_sparkline()` 创建折线图" |> gt () |> gt_plt_sparkline (Sepal.L) |> # 在 Sepal.L 列中添加折线图 gt_plt_sparkline (Sepal.W) |> # 在 Sepal.W 列中添加折线图 gt_plt_sparkline (Petal.L) |> # 在 Petal.L 列中添加折线图 gt_plt_sparkline (Petal.W) # 在 Petal.W 列中添加折线图 ``` #### 分布图 `gt_plt_dist()` 在表格单元中创建分布图。图表类型取决于 type 参数:`agg_iris` 汇总数据框:```{r} #| fig-cap: "使用 `gt_plt_dist()` 创建分布图" |> gt () |> gt_plt_dist (type = "density" # 密度图 |> gt_plt_dist (type = "boxplot" # 箱线图 |> gt_plt_dist (type = "histogram" # 直方图 |> gt_plt_dist (type = "rug_strip" # 裸条图 ``` #### 条形图 `gt_plt_bar_pct()` 不需要汇总数据。这个图表实际上是一个得分条形图, 最大值是 100% ```{r} #| fig-cap: "使用 `gt_plt_bar_pct()` 创建得分条形图" <- head (iris) |> gt () |> gt_plt_bar_pct (labels = TRUE , # 显示百分比标签 # scaled = FALSE # “我提供的是原始数值,它们还没有被处理成百分比,你需要自己动手去计算和缩放。” # scaled = TRUE # “你不需要做任何计算了。我提供给你的数值已经是最终百分比了,请直接使用。” |> gt_plt_bar_pct (labels= FALSE ,fill = "forestgreen" ``` #### 摘要图表 `gt_plt_summary()` 制作摘要图表,甚至还能交互查看,非常方便和美观```{r} #| fig-cap: "使用 `gt_plt_summary()` 制作摘要图表" |> gt_plt_summary ()``` #### 主题 ```{r} #| fig-cap: "`gt_theme_excel()` Excel 主题" head (mtcars) |> gt () |> gt_theme_excel ()``` ```{r} #| fig-cap: "`gt_theme_538()` 538(FiveThirtyEight) 主题" head (mtcars) |> gt () |> gt_theme_538 ()``` ```{r} #| fig-cap: "`gt_theme_espn()` ESPN 主题" head (mtcars) |> gt () |> gt_theme_espn ()``` ```{r} #| fig-cap: "`gt_theme_nytimes()` NY Times 主题" head (mtcars) |> gt () |> gt_theme_nytimes ()``` ```{r} #| fig-cap: "`gt_theme_dot_matrix()` 点阵 (dot matrix) 主题" head (mtcars) |> gt () |> gt_theme_dot_matrix ()``` ```{r} #| fig-cap: "`gt_theme_dark()` 黑暗主题" head (mtcars) |> gt () |> gt_theme_dark ()``` ```{r} head (mtcars) |> gt () |> gt_theme_pff ()``` ```{r} #| fig-cap: "`gt_theme_guardian()` 卫报 Guardian 主题" head (mtcars) |> gt () |> gt_theme_guardian ()``` ## `kable family` `kable()` 和 `kableExtra()` 用于 `Quarto` / `R Markdown` 文档### `kable()` ```r # `kable()` 用法演示 kable (# 数据框或矩阵 format = c ("pandoc" , "latex" , "HTML" ), # 输出格式 digits = getOption ("digits" ), # 小数点位数 row.names = FALSE , # 是否显示行名 col.names = TRUE , # 是否显示列名 align = c ("auto" , "left" , "center" , "right" ), # 对齐方式 caption = NULL , # 表格标题 ``` ```{r} #| fig-cap: "使用 `kable()` 创建表格" # 创建一个简单的数据框 = data.frame (Temp = c (1 , 2 , 3 , 4 ),Rain = c (12 , 42 , 17 , 9 ),Hum = c (21 , 24 , 71 , 90 )|> kable () # 创建一个简单的表格 ``` ### `kableExtra()` #### 基本 `kableExtra` 依赖于 `kable` 包,并允许使用 |> (管道)符号。主要功能名为 `kbl()` ,与 `kable()` 类似。```{r} #| fig-cap: "使用 `kableExtra::kbl()` 创建表格" |> kbl () |> kable_styling ()``` #### 颜色 ```{r} #| fig-cap: "使用 kableExtra 更改行列颜色和样式" |> kbl (align = "c" ) |> # 居中对齐所有列 kable_styling (full_width = FALSE ) |> # 表格宽度不自动拉伸 column_spec (2 , color = "red" ) |> # 第二列字体颜色设为红色 column_spec (1 , background = "green" ) |> # 第一列背景色设为绿色 row_spec (3 , color = "blue" ) |> # 第三行字体颜色设为蓝色 row_spec (4 , background = "yellow" ) # 第四行背景色设为黄色 ``` `color` 和 `background` 参数也可以接受颜色向量:```{r} #| fig-cap: "使用 kableExtra 为列设置颜色向量(每行不同颜色)" |> kbl (align = "c" ) |> # 所有列居中对齐 kable_styling (full_width = FALSE ) |> # 表格宽度不自动拉伸 # 为第三列设置不同的背景色,每一行对应一个颜色 column_spec (3 , background = c ("blue" , "red" , "black" , "blue" ))``` ```{r} #| fig-cap: "使用 kableExtra 为列设置渐变色和字体颜色(每行不同颜色)" # 生成渐变色函数,从 darkred 到 magenta <- colorRampPalette (c ("darkred" , "magenta" ))<- nrow (df) # 获取数据框的行数 <- colfunc (n_color) # 生成与数据行数相同的颜色向量 # 按照 Rain 列降序排列数据框 <- df |> arrange (desc (Rain))|> kbl (align = "c" ) |> # 所有列居中对齐 kable_styling (full_width = FALSE ) |> # 表格宽度不自动拉伸 column_spec (3 , background = colors) |> # 第三列设置为渐变背景色 column_spec (2 , color = colors) # 第二列字体颜色设置为渐变色 ``` #### 图片 ```{r} #| fig-cap: "使用 kableExtra 在表格中插入图片" # 创建一个包含姓名、领域和图片列的数据框 = data.frame (name = c ("E. Charpentier" , "R. Penrose" , "L. Glück" , "M. Houghton" ), # 姓名 field = c ("Chemistry" , "Physics" , "Litterature" , "Medicine" ), # 领域 image = "" # 图片列(占位) # 生成图片路径向量,每行对应一张图片 = rep ("./image/pikachu.png" , nrow (df))# 使用 kableExtra 创建表格并插入图片 |> kbl (booktabs = TRUE , align = "c" ) |> # 创建表格,booktabs 风格,所有列居中 kable_styling () |> # 应用默认表格美化样式 kable_paper (full_width = TRUE ) |> # 使用 paper 风格,表格宽度自适应 column_spec (3 , # 第三列(image 列) image = spec_image (path_images, 200 , 200 ) # 插入图片,宽高均为 200 像素 ``` #### 链接 ```{r} #| fig-cap: "使用 kableExtra 添加图片和超链接" # 生成图片路径向量,每行对应一张图片 = rep ("./image/pikachu.png" , nrow (df))# 定义每个人名对应的维基百科链接 = c ("https://en.wikipedia.org/wiki/Emmanuelle_Charpentier" ,"https://en.wikipedia.org/wiki/Roger_Penrose" ,"https://en.wikipedia.org/wiki/Louise_Glück" ,"https://en.wikipedia.org/wiki/Michael_Houghton" |> kbl (booktabs = TRUE , align = "c" ) |> # 创建表格,使用booktabs风格,所有列居中 kable_styling () |> # 应用默认的表格美化样式 kable_material (c ("striped" , "hover" , "condensed" , "responsive" )) |> # 应用Material风格,带斑马纹、悬停、紧凑和响应式 column_spec (1 , link = urls, bold = TRUE ) |> # 第一列(姓名)添加超链接并加粗 column_spec (3 , image = spec_image (path_images, 200 , 200 )) # 第三列插入图片,宽高均为200像素 ``` ## Interactive `DT` 、`reactable` 或 `formattable` 制作交互式表格### `DT` `DT` ([ 官方文档 ](https://github.com/rstudio/DT) ),即DataTables,基于 Javascript,DT 以其高效处理大型数据集的能力和丰富的功能(如搜索、排序和分页)而突出。#### 基本 `DT::datatable()` 函数:```{r} #| fig-cap: "使用 DT 包创建交互式表格:基本用法" data (mtcars)= datatable (mtcars)# 保存为 HTML 文件 # library(htmlwidgets) # 加载 htmlwidgets 包 # saveWidget(table, file="../HtmlWidget/dt-table-basic.html") # 保存为 HTML 文件 ``` #### CSS 类 ```{r} #| fig-cap: "使用 DT 包创建交互式表格:添加 CSS 类" = datatable (class = 'cell-border stripe hover compact' ``` #### 标题 ```{r} #| fig-cap: "使用 DT 包创建交互式表格:添加标题" # 使用 datatable() 创建交互式表格,并添加标题 <- datatable (# 数据集,内置的汽车数据 caption = tags$ caption (style = 'caption-side: bottom; text-align: center;' , # 设置标题样式:底部居中 'Table 1: ' , # 标题前缀 em ('The mtcars dataset is a dataset about cars properties' ) # 斜体副标题 # 显示表格 ``` #### 筛选 ```{r} #| fig-cap: "使用 DT 包创建交互式表格:添加筛选器" <- datatable (mtcars,filter = "top" , # 在表格顶部添加筛选器 ``` #### Callback `callback` 参数将 `JavaScript` 函数用在表格中:```{r} #| fig-cap: "使用 DT 包创建交互式表格:添加 JavaScript 回调" <- datatable (mtcars, callback = JS ('table.page("next").draw(false);' ))``` #### 编辑 ```{r} #| fig-cap: "使用 DT 包创建可编辑的交互式表格" <- datatable (editable = list (target = "row" ,disable = list (columns = c (1 , 3 , 5 ))# 显示可编辑的表格 ``` #### 定制 ```{r} #| fig-cap: "使用 DT 包创建带有 HTML 内容和自定义列名的交互式表格" # 创建一个包含 HTML 内容的数据集 = matrix (c ('<b>Bold</b>' , # 第一行第一列,粗体 HTML 标签 '<em>Emphasize</em>' , # 第二行第一列,斜体 HTML 标签 '<a href="https://r-graph-gallery.com/package/dt.html">Click here</a>' , # 第一行第二列,带链接的 HTML 标签 '<a href="#" onclick="alert( \' This message is displayed thanks to DT table! \' );">Click there</a>' # 第二行第二列,点击弹窗的 HTML 标签 2 # 指定矩阵有两列 # 修改列名,使用 HTML 语法自定义样式 colnames (data) = c ('<span style="color:red">Red column</span>' , # 第一列名为红色字体 '<em>Italic column</em>' # 第二列名为斜体 # 创建 DT 交互式表格 <- datatable (escape = FALSE # 允许单元格内容作为 HTML 解释(否则会转义为纯文本) # 显示表格 ``` ### `reactable` #### 基本 ```{r} #| label: "reactable-basic" #| fig-cap: "使用 `reactable()` 创建交互式表格:基本用法" = data.frame (date = as.POSIXct (c ("2019-01-02 3:22:15" , "2019-03-15 09:15:55" , "2019-09-22 14:20:00" ),tz = "America/New_York" currency = c (1000 , 2000 , 3000 ),temperature = c (10 , 20 , 30 ),percentage = c (0.12 , 0.23 , 0.34 )<- (reactable (df))embed_widget (tab, height = "300px" )``` #### 日期 `colFormat()` 函数来格式化日期`format` 参数来自定义日期格式,有三种日期格式: `datetime` 、`date` 和 `time` 。```{r} #| label: "reactable-datetime" #| fig-cap: "使用 `reactable::colFormat()` 格式化日期、时间和本地化显示" # 创建一个包含不同时间格式的数据框 <- as.POSIXct (c ("2019-01-02 3:22:15" , "2019-03-15 09:15:55" , "2019-09-22 14:20:00" ),tz = "America/New_York" <- data.frame (datetime = datetimes, # 日期时间列 date = datetimes, # 仅日期列 time = datetimes, # 仅时间列(12小时制) time_24h = datetimes, # 仅时间列(24小时制) datetime_pt_BR = datetimes # 用于本地化显示的日期时间列 # 使用 reactable 创建交互式表格,并对不同列应用不同的日期/时间格式 <- reactable (columns = list (datetime = colDef (format = colFormat (datetime = TRUE )), # 显示完整日期时间 date = colDef (format = colFormat (date = TRUE )), # 仅显示日期 time = colDef (format = colFormat (time = TRUE )), # 仅显示时间(12小时制) time_24h = colDef (format = colFormat (time = TRUE , hour12 = FALSE )), # 仅显示时间(24小时制) datetime_pt_BR = colDef (format = colFormat (datetime = TRUE , locales = "zh-CN" ) # 按中国北京时间显示日期时间 embed_widget (tab, height = "300px" )``` #### 货币 ```{r} #| label: "reactable-currency" #| fig-cap: "使用 `reactable::colFormat()` 格式化多种货币并本地化显示" # 创建一个包含多种货币的数据框 = data.frame (USD = c (12.12 , 2141.213 , 0.42 , 1.55 , 34414 ), # 美元 EUR = c (10.68 , 1884.27 , 0.37 , 1.36 , 30284.32 ), # 欧元 INR = c (861.07 , 152122.48 , 29.84 , 110 , 2444942.63 ), # 印度卢比 JPY = c (1280 , 226144 , 44.36 , 164 , 3634634.61 ), # 日元 MAD = c (115.78 , 20453.94 , 4.01 , 15 , 328739.73 ) # 摩洛哥迪拉姆 # 使用 reactable 创建交互式表格,并对每一列应用不同的货币格式和本地化设置 = reactable (columns = list (USD = colDef (# 美元,千分位分隔符,英文美国本地化 format = colFormat (currency = "USD" , separators = TRUE , locales = "en-US" )EUR = colDef (# 欧元,千分位分隔符,德语德国本地化 format = colFormat (currency = "EUR" , separators = TRUE , locales = "de-DE" )INR = colDef (# 印度卢比,千分位分隔符,印地语印度本地化 format = colFormat (currency = "INR" , separators = TRUE , locales = "hi-IN" )JPY = colDef (# 日元,千分位分隔符,日语日本本地化 format = colFormat (currency = "JPY" , separators = TRUE , locales = "ja-JP" )MAD = colDef (# 摩洛哥迪拉姆,千分位分隔符,阿拉伯语摩洛哥本地化 format = colFormat (currency = "MAD" , separators = TRUE , locales = "ar-MA" )embed_widget (tab, height = "300px" )``` #### 数字 ```{r} #| label: "reactable-num" #| fig-cap: "使用 `reactable::colFormat()` 格式化数字列" # 创建一个包含温度和百分比的数据框 <- data.frame (temperature = c (10 , 20 , 30 ), # 温度列,单位为摄氏度 percentage = c (0.12 , 0.23 , 0.34 ) # 百分比列,原始值为小数 # 使用 reactable 创建交互式表格,并对不同列进行格式化 <- reactable (columns = list (# 对 temperature 列添加后缀“°C” temperature = colDef (format = colFormat (suffix = " °C" )),# 对 percentage 列格式化为百分比,并添加前缀“Percent: ” percentage = colDef (format = colFormat (percent = TRUE , prefix = "Percent: " )embed_widget (tab, height = "200px" )``` #### 图片表格 ```{r} #| label: "reactable-image" #| fig-cap: "使用 reactable 和 reactablefmtr 制作带图片和数据条的网球冠军表格" library (tidyverse) # 数据处理与可视化 library (reactablefmtr) # reactable 扩展包,用于数据条、色阶等 library (reactable) # 交互式表格 library (htmltools) # HTML 工具包 library (webshot2) # 网页截图 # 读取数据 <- read_csv (" rank,player,years,australian_open,french_open,us_open,wimbledon,titles,region 1,Margaret Court,1960–1973,11,5,5,3,24,https://raw.githubusercontent.com/catamphetamine/country-flag-icons/master/flags/1x1/AU.svg 2,Serena Williams,1999–2017,7,3,6,7,23,https://raw.githubusercontent.com/catamphetamine/country-flag-icons/master/flags/1x1/US.svg 3,Steffi Graf,1987–1999,4,6,5,7,22,https://raw.githubusercontent.com/catamphetamine/country-flag-icons/master/flags/1x1/DE.svg 4,Helen Wills Moody,1923–1938,0,4,7,8,19,https://raw.githubusercontent.com/catamphetamine/country-flag-icons/master/flags/1x1/US.svg 5,Chris Evert,1974–1986,2,7,6,3,18,https://raw.githubusercontent.com/catamphetamine/country-flag-icons/master/flags/1x1/US.svg 5,Martina Navratilova,1978–1990,3,2,4,9,18,https://raw.githubusercontent.com/catamphetamine/country-flag-icons/master/flags/1x1/US.svg 6,Billie Jean King,1966–1975,1,1,4,6,12,https://raw.githubusercontent.com/catamphetamine/country-flag-icons/master/flags/1x1/US.svg 7,Maureen Connolly,1951–1954,1,2,3,3,9,https://raw.githubusercontent.com/catamphetamine/country-flag-icons/master/flags/1x1/US.svg 7,Monica Seles,1990–1996,4,3,2,0,9,https://raw.githubusercontent.com/catamphetamine/country-flag-icons/master/flags/1x1/US.svg 8,Molla Bjurstedt Mallory,1915–1922,0,0,8,0,8,https://raw.githubusercontent.com/catamphetamine/country-flag-icons/master/flags/1x1/FR.svg 8,Suzanne Lenglen,1919–1926,0,2,0,6,8,https://raw.githubusercontent.com/catamphetamine/country-flag-icons/master/flags/1x1/US.svg " # 自定义色阶调色板,用于色阶填充 <- c ("#F4FFFD" , "#E9DAEC" , "#A270E5" , "#43009A" )# 主体表格,注意字体需本地安装 <- reactable (|> :: select ( # 还起到一个排序的作用 theme = reactableTheme (borderColor = "#DADADA" # 边框颜色 defaultPageSize = 11 , # 默认每页显示11行 defaultColDef = colDef (vAlign = "center" , # 垂直居中 align = "center" , # 水平居中 headerVAlign = "center" , # 表头垂直居中 style = color_scales (df, span = 4 : 7 , colors = pal_scale), # 4~7列使用色阶填充 width = 90 # 列宽 columnGroups = list (colGroup (name = "" , # 分组名为空 columns = c ("player" , "region" , "titles" ), # 分组列 align = "left" # 左对齐 colGroup (name = "Event" , # 分组名 columns = c ("australian_open" , "us_open" , "french_open" , "wimbledon" ), # 大满贯赛事列 columns = list (rank = colDef (show = FALSE ), # 隐藏rank列 player = colDef (name = "Player (First Title - Last Title)" , # 列名 align = "left" , # 左对齐 width = 250 , # 列宽 # 自定义单元格内容:显示球员头像+姓名+年份 cell = function (value) {<- img (src = paste0 ("https://raw.githubusercontent.com/tashapiro/tanya-data-viz/main/tennis/images/" ,str_replace_all (tolower (value), " " , "_" ),".png" style = "height: 33px;" ,alt = valuetagList (div (style = "display: inline-block;vertical-align:middle;width:50px" ,div (style = "display: inline-block;vertical-align:middle;" ,div (style = "vertical-align:middle;" , value),div (style = "vertical-align:middle;font-size:8pt;color:#8C8C8C;" ,paste0 ("(" , df[df$ player == value, ]$ years),")" region = colDef (name = "Region" , # 列名 align = "left" , # 左对齐 # 自定义单元格内容:显示国旗图片,部分球员加星号 cell = function (value, index) {<- img (src = value,style = "width:60px;height:20px;" ,alt = value<- df$ player[index]if (player %in% c ("Monica Seles" , "Molla Bjurstedt Mallory" )) {tagList (div (style = "display:inline-block;vertical-align:middle;width:80px" ,"*" else {tagList (div (style = "display:inline-block;vertical-align:middle;width:50px" ,width = 120 # 列宽 australian_open = colDef (name = "AU Open" ), # 澳网 french_open = colDef (name = "FR Open" ), # 法网 us_open = colDef (name = "US Open" ), # 美网 wimbledon = colDef (name = "Wmbl" ), # 温网 titles = colDef (name = "Total Titles" , # 列名 width = 180 , # 列宽 class = "border-left" , # 左边加边框 align = "left" , # 左对齐 # 使用数据条可视化总冠军数 cell = data_bars (fill_color = "#7814ff" , # 数据条颜色 text_position = "outside-end" , # 数字显示在条形外部 bar_height = 10 , # 条形高度 text_size = 12 , # 数字字体大小 min_value = 5 , # 最小值 max_value = 32 , # 最大值 background = "transparent" # 背景透明 # 添加标题、子标题、脚注和数据来源 # 字体需本地安装(如 Font Awesome 图标字体) <- table |> :: prependContent (tagList (# 网球logo $ img (src = "https://pngimg.com/uploads/tennis/tennis_PNG10416.png" ,style = "width:50px;height:34px;display:inline-block;vertical-align:middle;" # 主标题 $ div ("Grand Slam Legends" ,style = "font-size:32px;font-weight:bold;font-family:sans-serif;margin-bottom:0;display:inline-block;vertical-align:middle;" # 副标题 $ h3 ("Top Women's Tennis Players by Singles Championship Titles" ,style = "font-family:sans-serif;margin-bottom:0;margin-top:0;font-weight:400;color:#8C8C8C;padding-left:10px;" |> :: appendContent (# 脚注 $ div ("* Player represented more than one country during career. Most recent country shown." ,style = "font-family:Roboto;color:black;font-size:9pt;border-bottom-style:solid;border-top-style:solid;width:910px;padding-bottom:8px;padding-top:8px;border-color:#DADADA;" # 数据来源 $ div ($ div ("Data: Wikipedia as of November 2022 | Graphic: " ,style = "display:inline-block;vertical-align:middle;" $ div ("twitter" ,style = "font-family:'Font Awesome 6 Brands';display:inline-block;vertical-align:middle;" $ div ("tanya_shapiro" ,style = "display:inline-block;vertical-align:middle;" $ div ("github" ,style = "font-family:'Font Awesome 6 Brands';display:inline-block;vertical-align:middle;" $ div ("tashapiro" ,style = "display:inline-block;vertical-align:middle;" style = "font-family:sans-serif;color:#8C8C8C;font-size:10pt;width:910px;padding-top:8px;display:inline-block;vertical-align:middle;" embed_widget (table_final)``` ### `formattable` `formattable` 是另一个创建交互式表格的 R 包。#### 基础 `formattable` 提供了几种典型的可格式化对象,如 `percent` 、`comma` 、`currency` 、`accounting` 和 `scientific` 。```{r} #| label: "formattable-basic" #| fig-cap: "使用 formattable 包创建格式化对象" #| comment: "#>" #| collapse: TRUE #| code-fold: false # 百分比 percent (c (0.1 , 0.02 , 0.03 , 0.12 ))# 百分比可运算 percent (c (0.1 , 0.02 , 0.03 , 0.12 )) + 0.05 # 货币 <- accounting (c (1000 , 500 , 200 , - 150 , 0 , 1200 ))# 货币可运算 + 1000 # 布尔 formattable (c (TRUE , TRUE , FALSE , FALSE , TRUE ), "yes" , "no" )# 格式化后的表格 data.frame (id = c (1 , 2 , 3 , 4 , 5 ),name = c ("A1" , "A2" , "B1" , "B2" , "C1" ),balance = accounting (c (52500 , 36150 , 25000 , 18300 , 7600 ), format = "d" ),growth = percent (c (0.3 , 0.3 , 0.1 , 0.15 , 0.15 ), format = "d" ),ready = formattable (c (TRUE , TRUE , FALSE , FALSE , TRUE ), "yes" , "no" )``` #### 表格 ```{r} #| fig-cap: "用于 `formattable` 的原始数据" <- data.frame (id = 1 : 10 ,name = c ("Bob" ,"Ashley" ,"James" ,"David" ,"Jenny" ,"Hans" ,"Leo" ,"John" ,"Emily" ,"Lee" age = c (28 , 27 , 30 , 28 , 29 , 29 , 27 , 27 , 31 , 30 ),grade = c ("C" , "A" , "A" , "C" , "B" , "B" , "B" , "A" , "C" , "C" ),test1_score = c (8.9 , 9.5 , 9.6 , 8.9 , 9.1 , 9.3 , 9.3 , 9.9 , 8.5 , 8.6 ),test2_score = c (9.1 , 9.1 , 9.2 , 9.1 , 8.9 , 8.5 , 9.2 , 9.3 , 9.1 , 8.8 ),final_score = c (9 , 9.3 , 9.4 , 9 , 9 , 8.9 , 9.25 , 9.6 , 8.8 , 8.7 ),registered = c (TRUE ,FALSE ,TRUE ,FALSE ,TRUE ,TRUE ,TRUE ,FALSE ,FALSE ,FALSE stringsAsFactors = FALSE # 避免自动转化为因子 |> formattable (caption = "用于 `formattable` 的格式化前的数据" )``` `formattable()` 创建一个漂亮的表格```{r} #| fig-cap: "使用 formattable 包创建带有条件格式和图标的交互式表格" library (formattable) formattable (list (# age 列:使用 color_tile() 为单元格添加从白色到橙色的渐变色背景 age = color_tile ("white" , "orange" ),# grade 列:A 等级为绿色加粗,其余不变 grade = formatter ("span" ,style = x ~ ifelse (x == "A" , formattable:: style (color = "green" , font.weight = "bold" ), NA )# test1_score 和 test2_score 列:normalize_bar() 添加粉色条形图,宽度最小为 0.2 area (col = c (test1_score, test2_score)) ~ normalize_bar ("pink" , 0.2 ),# final_score 列:前 3 名为绿色,其余为灰色,并显示分数和排名 final_score = formatter ("span" ,style = x ~ formattable:: style (color = ifelse (rank (- x) <= 3 , "green" , "gray" )),~ sprintf ("%.2f (rank: %02d)" , x, rank (- x))# registered 列:TRUE 为绿色“ok”图标和 Yes,FALSE 为红色“remove”图标和 No registered = formatter ("span" ,style = x ~ formattable:: style (color = ifelse (x, "green" , "red" )),~ icontext (ifelse (x, "ok" , "remove" ), ifelse (x, "Yes" , "No" ))``` ## Other ### `flextable` `flextable` ([ 官方文档 ](https://github.com/davidgohel/flextable) ) 是创建非常精致静态表格的另一个可靠选项。它支持多种格式选项,包括合并单元格、旋转文本和条件格式化。```r # 这段代码不会被执行 flextable (iris) |> theme_vanilla () |> save_as_docx (path = "mytable.docx" ) # 导出为word文档 ``` ```{r} #| fig-cap: "使用 flextable 包创建精致的静态表格,并自定义字体、字号、边框颜色等样式" library (flextable)# 设置 flextable 的默认参数 set_flextable_defaults (font.family = "Arial" , # 设置字体为 Arial font.size = 10 , # 设置字体大小为 10 border.color = "gray" , # 设置边框颜色为灰色 big.mark = "" # 千分位分隔符为空 # 创建 flextable 表格对象 <- flextable (head (mtcars)) |> :: bold (part = "header" ) # 表头加粗 ``` ```{r} #| fig-cap: "使用 flextable 包创建精致的静态表格,并自定义高亮、背景色和添加脚注" |> highlight (i = ~ mpg < 22 , # 选择 mpg 小于 22 的行 j = "disp" , # 仅对 disp 列进行高亮 color = "#ffe842" # 设置高亮颜色为黄色 |> bg (j = c ("hp" , "drat" , "wt" ), # 对 hp、drat、wt 三列设置背景色 bg = scales:: col_quantile ( # 使用分位数调色板自动分配背景色 palette = c ("wheat" , "red" ), # 渐变色从 wheat 到 red domain = NULL # 自动根据数据范围计算分位数 |> add_footer_lines ("The 'mtcars' dataset" # 在表格底部添加脚注说明 ``` ```{r} #| fig-cap: "使用 flextable 包对 diamonds 数据集按 cut 分组汇总并美观展示" :: diamonds[, c ("cut" , "carat" , "price" , "clarity" , "table" )] |> summarizor (by = c ("cut" )) |> # summarizor: 按 cut 分组汇总数据 :: as_flextable (spread_first_col = TRUE ) # as_flextable: 转为 flextable 表格,spread_first_col=TRUE 将第一列展开为分组标签 ``` ### `rhandsontable` `Rhandsontable` 提供了一个交互式表格界面,允许在 `Shiny` 应用或 `R Markdown` 文档中直接编辑表格。它通过下拉菜单、复选框和日历辅助工具等特性,区别于其他工具,强调交互性和用户输入。`Shiny` 应用程序。```{r} #| label: "rhandsontable-basic" #| fig-cap: "使用 rhandsontable 包创建可交互编辑的表格,并在 'chart' 列中嵌入 sparkline 迷你图" # 由于Quarto渲染问题,所以不执行这段代码 = data.frame (int = 1 : 10 , # 整数列 numeric = rnorm (10 ), # 正态分布的数值列 logical = TRUE , # 逻辑值列,全部为 TRUE character = LETTERS[1 : 10 ], # 字符型列,A~J fact = factor (letters[1 : 10 ]), # 因子型列,a~j date = seq (from = Sys.Date (), by = "days" , length.out = 10 ), # 日期列,从今天起连续10天 stringsAsFactors = FALSE # 不自动转为因子 # 添加 sparkline 迷你图数据列,每行生成一个包含10个正态分布随机数的 JSON $ chart = sapply (1 : 10 , function (x) jsonlite:: toJSON (list (values = rnorm (10 ))))# 创建 rhandsontable 交互式表格 <- rhandsontable (df, rowHeaders = NULL ) |> # rowHeaders = NULL 不显示行名 hot_col ("chart" , # 指定 chart 列 renderer = htmlwidgets:: JS ("renderSparkline" ) # 使用 JS 渲染 sparkline 迷你图 embed_widget (p, height = "300px" )``` ### `modelsummary` #### 介绍 [ modelsummary ](https://github.com/vincentarelbundock/modelsummary?tab=readme-ov-file) - `modelsummary` : 并列模型回归表。- `modelplot` : 系数图。- `datasummary` : 创建(多级)交叉表和数据摘要的强大工具。- `datasummary_crosstab` : 交叉表。- `datasummary_balance` : 基线表,包含子组统计和均值差异(又名 “*table 1*” )。- `datasummary_correlation` : 相关性表格。- `datasummary_skim` : 数据集的快速概览(“skim”)。- `datasummary_df` : 将数据框转换为带有标题、注释等的漂亮表格。#### 特点 ```{r} library (modelsummary)<- lm (Sepal.Width ~ Sepal.Length, iris) # 建模 modelsummary (mod, output = "markdown" ) # 输出为 markdown 格式,还可以输出docx / tex 格式 # modelsummary(mod, output = "table.docx") # modelsummary(mod, output = "table.tex") ``` - 信息:该软件包提供了许多直观且强大的工具,用于自定义摘要表中报告的信息。- 外观:无线定制- 支持的模型:得益于 `broom` 和 `parameters` , `modelsummary` 默认支持数百种统计模型。- 输出格式: `HTML` 、`LaTeX` 、文本 / `Markdown` 、`Word` 、`Powerpoint` 、`RTF` 、`JPG` 或 `PNG` 格式 {width="65%"}### `huxtable` `LaTeX` 输出[ huxtable ](https://github.com/hughjonesd/huxtable) #### 基本 ```{r} #| fig-cap: "使用 `huxtable` 包创建 `LaTeX` 表格并自定义样式" library (huxtable)<- data.frame (Employee = c ("John Smith" , "Jane Doe" , "David Hugh-Jones" ),Salary = c (50000 , 50000 , 40000 ),add_colnames = TRUE <- hux (df)# 将第一行(表头)加粗 bold (ht)[1 , ] <- TRUE # 设置第一行底部边框宽度为 0.4 bottom_border (ht)[1 , ] <- 0.4 # 设置第二列(Salary)右对齐 align (ht)[, 2 ] <- "right" # 设置所有单元格右侧内边距为 10 right_padding (ht) <- 10 # 设置所有单元格左侧内边距为 10 left_padding (ht) <- 10 # 设置表格宽度为 0.35(相对于页面宽度) width (ht) <- 0.35 # 设置所有单元格数字格式为保留 2 位小数 number_format (ht) <- 2 # 查看表格 ``` #### 管道 ```{r} #| fig-cap: "使用 `huxtable` 包管道风格创建 `LaTeX` 表格并自定义样式" <- hux (Employee = c ("John Smith" , "Jane Doe" , "David Hugh-Jones" ), # 员工姓名 Salary = c (50000 , 50000 , 40000 ) # 薪资 |> set_bold (1 , everywhere) |> # 第一行(表头)加粗,everywhere 表示所有列 set_bottom_border (1 , everywhere) |> # 第一行底部加边框 set_align (everywhere, 2 , "right" ) |> # 第二列(薪资)右对齐 set_lr_padding (10 ) |> # 左右内边距均为10 set_width (0.35 ) |> # 表格宽度为页面的0.35 set_number_format (2 ) # 数字保留2位小数 ``` #### 格式化 ```{r} #| fig-cap: "使用 `huxtable` 包格式化 `LaTeX` 表格:文本颜色、背景色、斜体和边框" 1 : 5 ] |> as_huxtable (add_rownames = "Model" ) |> # 将数据框转换为 huxtable,并添加行名列“Model” set_bold (1 , everywhere, TRUE ) |> # 第一行(表头)所有列加粗 set_all_borders (1 ) |> # 所有单元格加边框,宽度为1 map_text_color (everywhere, "mpg" , by_colorspace ("navy" , "red" , "yellow" )) |> # mpg 列根据数值映射文本颜色(深蓝-红-黄渐变) map_background_color ("hp" ,by_quantiles (0.8 , c ("white" , "yellow" )) # hp 列按分位数映射背景色(白-黄) |> map_italic (everywhere, "Model" , by_regex ("Merc.*" = TRUE )) |> # Model 列名以 Merc 开头的行斜体 head (12 ) # 取前12行 ``` #### 多回归表 ```{r} #| fig-cap: "使用 `huxtable` 包的 `huxreg()` 创建多模型回归结果表格,并详细注释各参数" data (diamonds, package = "ggplot2" )<- lm (log (price) ~ carat, diamonds) # 线性回归模型1:以 carat 预测 log(price) <- lm (log (price) ~ depth, diamonds) # 线性回归模型2:以 depth 预测 log(price) <- lm (log (price) ~ carat + depth, diamonds) # 线性回归模型3:以 carat 和 depth 预测 log(price) # huxreg() 用于并排展示多个回归模型结果 # 参数说明: # lm1, lm2, lm3:要比较的多个回归模型对象 # statistics:自定义底部统计量,N 表示样本量(nobs),R2 表示决定系数(r.squared) huxreg (statistics = c ("N" = "nobs" , "R2" = "r.squared" )``` #### 快速文档 ```r # 这段代码不会被执行 quick_pdf (mtcars)quick_docx (mtcars)quick_html (mtcars)quick_xlsx (mtcars)``` ## Pearl [ Tidyverse in Numbers ](https://r-graph-gallery.com/web-interactive-table-with-inline-labels-images-and-charts.html) 美观的带有图片的交互式表格。


