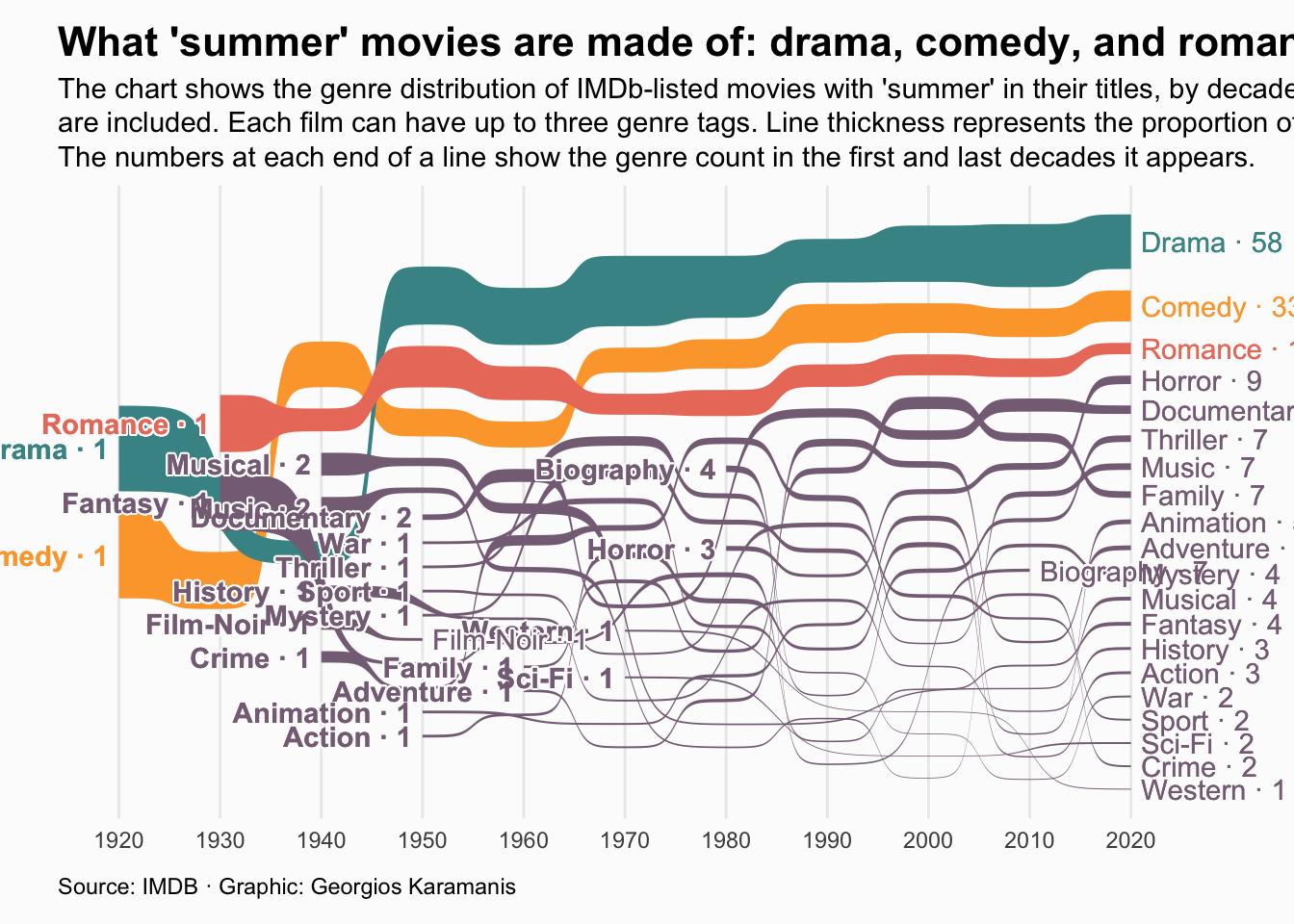
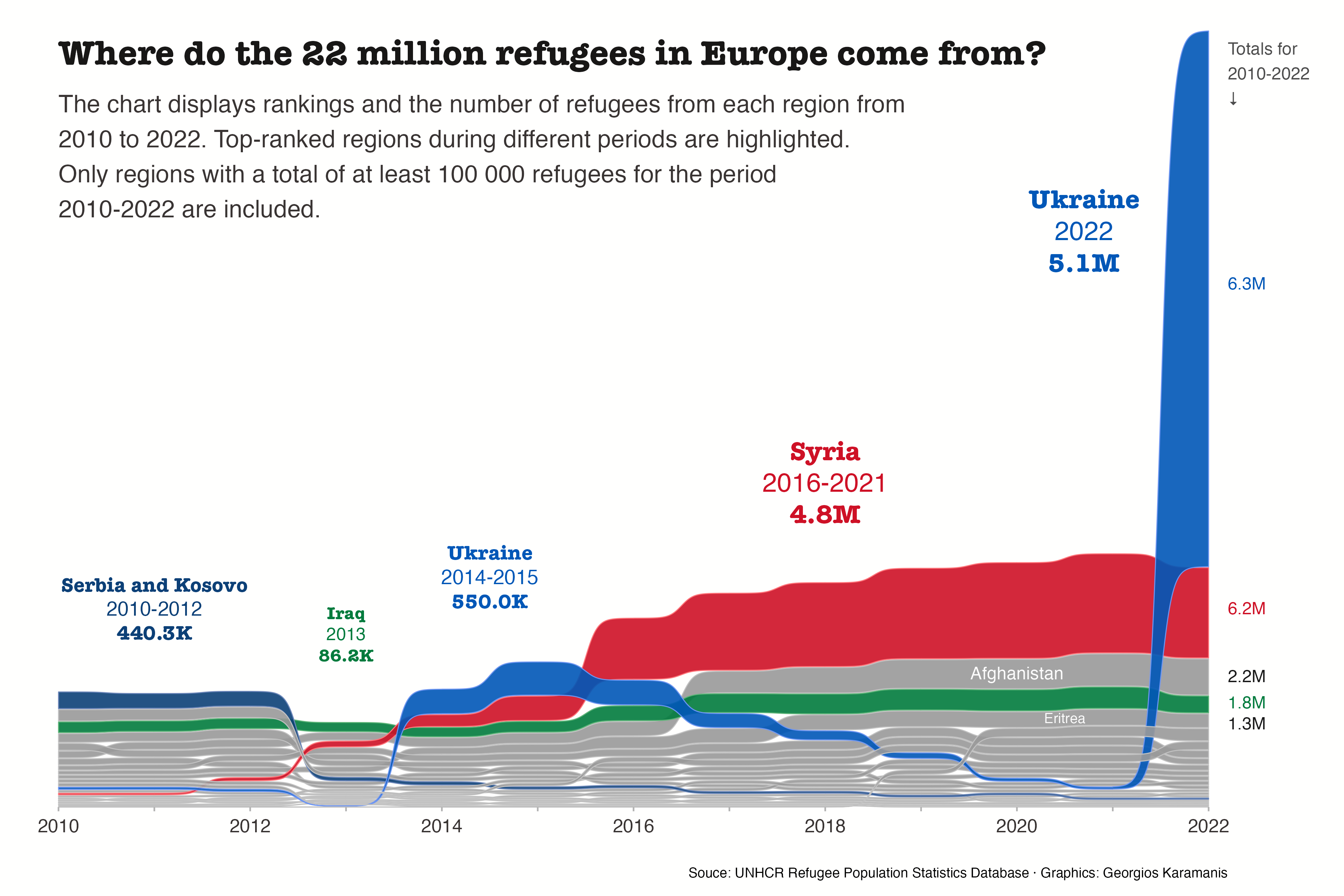
Show/Hide Code
library(tidyverse) # 数据处理核心包
library(viridis) # 颜色方案
library(patchwork) # 图形拼接
library(hrbrthemes) # 图形主题
library(circlize) # 圆形图形
library(networkD3) # 创建网络图和桑基图
library(jsonlite) # 解析JSON数据
library(dplyr) # 用于数据处理library(tidyverse) # 数据处理核心包
library(viridis) # 颜色方案
library(patchwork) # 图形拼接
library(hrbrthemes) # 图形主题
library(circlize) # 圆形图形
library(networkD3) # 创建网络图和桑基图
library(jsonlite) # 解析JSON数据
library(dplyr) # 用于数据处理# 加载必要的库
library(tidyverse) # 数据处理核心包
library(viridis) # 颜色方案
library(patchwork) # 图形拼接
library(hrbrthemes) # 图形主题
library(circlize) # 圆形图形
library(networkD3) # 网络图和桑基图
# 从GitHub加载数据集
data <- read.table(
"https://raw.githubusercontent.com/holtzy/data_to_viz/master/Example_dataset/13_AdjacencyDirectedWeighted.csv",
header = TRUE
)
# 转换为长格式数据
data_long <- data |>
rownames_to_column() |> # 行名转为列
gather(key = "key", value = "value", -rowname) |> # 宽转长
filter(value > 0) # 过滤正值
# 重命名列
colnames(data_long) <- c("source", "target", "value")
data_long$target <- paste(data_long$target, " ", sep = "") # 目标节点加空格区分
# 创建节点数据框:列出流程中涉及的所有实体
nodes <- data.frame(
name = c(as.character(data_long$source), as.character(data_long$target)) |>
unique()
)
# networkD3需要使用ID而非名称,重新格式化连接数据
data_long$IDsource <- match(data_long$source, nodes$name) - 1 # 源节点ID
data_long$IDtarget <- match(data_long$target, nodes$name) - 1 # 目标节点ID
# 准备颜色比例尺
ColourScal <- 'd3.scaleOrdinal() .range(["#FDE725FF","#B4DE2CFF","#6DCD59FF","#35B779FF","#1F9E89FF","#26828EFF","#31688EFF","#3E4A89FF","#482878FF","#440154FF"])'
# 创建桑基图
sankeyNetwork(
Links = data_long, # 连接数据
Nodes = nodes, # 节点数据
Source = "IDsource", # 源节点列名
Target = "IDtarget", # 目标节点列名
Value = "value", # 流量值列名
NodeID = "name", # 节点名称列名
sinksRight = FALSE, # 终点不强制右对齐
colourScale = ColourScal, # 颜色方案
nodeWidth = 40, # 节点宽度
fontSize = 13, # 字体大小
nodePadding = 20 # 节点间距
)基于迁移数据的桑基图:展示不同国家间人口流动情况
# 加载网络图包
library(networkD3)
# 加载能源投影数据
URL <- "https://cdn.rawgit.com/christophergandrud/networkD3/master/JSONdata/energy.json"
Energy <- jsonlite::fromJSON(URL) # 解析JSON数据
# 现在我们有两个数据框:
# - links数据框:包含3列(from, to, value)
# - nodes数据框:给出每个节点的名称
# 绘制桑基图
sankeyNetwork(
Links = Energy$links, # 连接数据
Nodes = Energy$nodes, # 节点数据
Source = "source", # 源节点列名
Target = "target", # 目标节点列名
Value = "value", # 流量值列名
NodeID = "name", # 节点名称列名
units = "TWh", # 单位标签
fontSize = 12, # 字体大小
nodeWidth = 30 # 节点宽度
)能源流向桑基图:展示能源从来源到终端的完整流向
从连接数据框 (Connection Data Frame) 创建桑基图:
# 加载所需的 R 包
library(networkD3) # 用于创建 D3 网络图
library(dplyr) # 用于数据处理
# 创建一个连接数据框 (links data frame)
# 这是一个表示流量信息的列表, 每一行代表一个从 source 到 target 的流量, 大小为 value
links <- data.frame(
source = c("group_A", "group_A", "group_B", "group_C", "group_C", "group_E"),
target = c("group_C", "group_D", "group_E", "group_F", "group_G", "group_H"),
value = c(2, 3, 2, 3, 1, 3)
)
# 从连接数据中, 我们需要创建一个节点数据框 (nodes data frame)
# 它列出了所有参与流动的实体 (节点)
nodes <- data.frame(
name = c(
as.character(links$source),
as.character(links$target)
) |>
unique() # 获取所有唯一的节点名称
)
# networkD3 需要使用从 0 开始的数字 ID 来表示连接, 而不是用节点名称
# 因此, 我们需要将 links 数据框中的名称转换为对应的 ID
links$IDsource <- match(links$source, nodes$name) - 1
links$IDtarget <- match(links$target, nodes$name) - 1
# 使用 sankeyNetwork 函数创建桑基图
p <- sankeyNetwork(
Links = links, # 连接数据框
Nodes = nodes, # 节点数据框
Source = "IDsource", # 连接源的 ID列
Target = "IDtarget", # 连接目标的 ID列
Value = "value", # 流量值的列
NodeID = "name", # 节点名称的列
sinksRight = FALSE # 如果为 TRUE, 没有出向连接的节点会靠右对齐
)
# 显示图表
p从连接数据框生成的基础桑基图
# 加载必要的库
library(networkD3)
library(dplyr)
# 创建连接数据框
links <- data.frame(
source = c("group_A", "group_A", "group_B", "group_C", "group_C", "group_E"),
target = c("group_C", "group_D", "group_E", "group_F", "group_G", "group_H"),
value = c(2, 3, 2, 3, 1, 3)
)
# 从连接流中创建节点数据框:列出流中涉及的所有实体
nodes <- data.frame(
name = c(as.character(links$source), as.character(links$target)) |>
unique()
)
# 使用networkD3时,连接必须使用id而不是链接数据框中的真实名称,因此需要重新格式化
links$IDsource <- match(links$source, nodes$name) - 1
links$IDtarget <- match(links$target, nodes$name) - 1
# 准备颜色比例:为每个节点指定特定颜色
my_color <- 'd3.scaleOrdinal() .domain(["group_A", "group_B","group_C", "group_D", "group_E", "group_F", "group_G", "group_H"]) .range(["blue", "blue" , "blue", "red", "red", "yellow", "purple", "purple"])'
# 创建网络图,使用colourScale参数调用颜色比例
p <- sankeyNetwork(
Links = links, Nodes = nodes, Source = "IDsource", Target = "IDtarget",
Value = "value", NodeID = "name", colourScale = my_color
)
p桑基图网络可视化
# 向节点数据框添加'group'列
nodes$group <- as.factor(c("a", "a", "a", "a", "a", "b", "b", "b"))
# 为每个组指定颜色
my_color <- 'd3.scaleOrdinal() .domain(["a", "b"]) .range(["#69b3a2", "steelblue"])'
# 创建网络图
p <- sankeyNetwork(
Links = links, Nodes = nodes, Source = "IDsource", Target = "IDtarget",
Value = "value", NodeID = "name",
colourScale = my_color, NodeGroup = "group"
)
p分组桑基图网络可视化
# 向每个连接添加'group'列
links$group <- as.factor(c("type_a", "type_a", "type_a", "type_b", "type_b", "type_b"))
# 向每个节点添加'group'列,这里将所有节点放在同一组中使其显示为灰色
nodes$group <- as.factor(c("my_unique_group"))
# 为每个组指定颜色
my_color <- 'd3.scaleOrdinal() .domain(["type_a", "type_b", "my_unique_group"]) .range(["#69b3a2", "steelblue", "grey"])'
# 创建网络图
p <- sankeyNetwork(
Links = links, Nodes = nodes, Source = "IDsource", Target = "IDtarget",
Value = "value", NodeID = "name",
colourScale = my_color, LinkGroup = "group", NodeGroup = "group"
)
p连接和节点分组的桑基图网络可视化
library(networkD3)
# 读取数据
URL <- "https://cdn.rawgit.com/christophergandrud/networkD3/master/JSONdata/energy.json"
Energy <- jsonlite::fromJSON(URL)
# 查看数据
head( Energy$links )
#> source target value
#> 1 0 1 124.729
#> 2 1 2 0.597
#> 3 1 3 26.862
#> 4 1 4 280.322
#> 5 1 5 81.144
#> 6 6 2 35.000
head( Energy$nodes )
#> name
#> 1 Agricultural 'waste'
#> 2 Bio-conversion
#> 3 Liquid
#> 4 Losses
#> 5 Solid
#> 6 Gas
# 绘制桑基图
p <- sankeyNetwork(
Links = Energy$links, # 连接数据
Nodes = Energy$nodes, # 节点数据
Source = "source", # 源节点列名
Target = "target", # 目标节点列名
Value = "value", # 流量值列名
NodeID = "name", # 节点名称列名
units = "TWh", # 单位标签
fontSize = 12, # 字体大小
nodeWidth = 30 # 节点宽度
)
p能源流向桑基图:展示能源从来源到终端的完整流向