# Spider {#sec-spider}
蛛网图, 又称雷达图. 缺点不少, 在数据科学领域不推荐使用.
## PKG
```{r}
library(fmsb) # 用于绘制雷达图
library(RColorBrewer) # 用于生成颜色
library(scales) # 用于设置透明度
library(tidyverse) # 用于数据处理和可视化
library(hrbrthemes) # 用于美化图表主题
library(colormap) # 用于生成颜色映射
library(GGally) # 用于绘制平行坐标图
library(viridis) # 用于生成颜色映射
# remotes::install_github("ricardo-bion/ggradar")
library(ggradar) # 用于绘制雷达图
library(palmerpenguins) # 用于示例企鹅数据集
library(scales) # 用于设置透明度
library(showtext) # 用于加载字体
showtext_auto() # 自动加载字体
```
## 问题
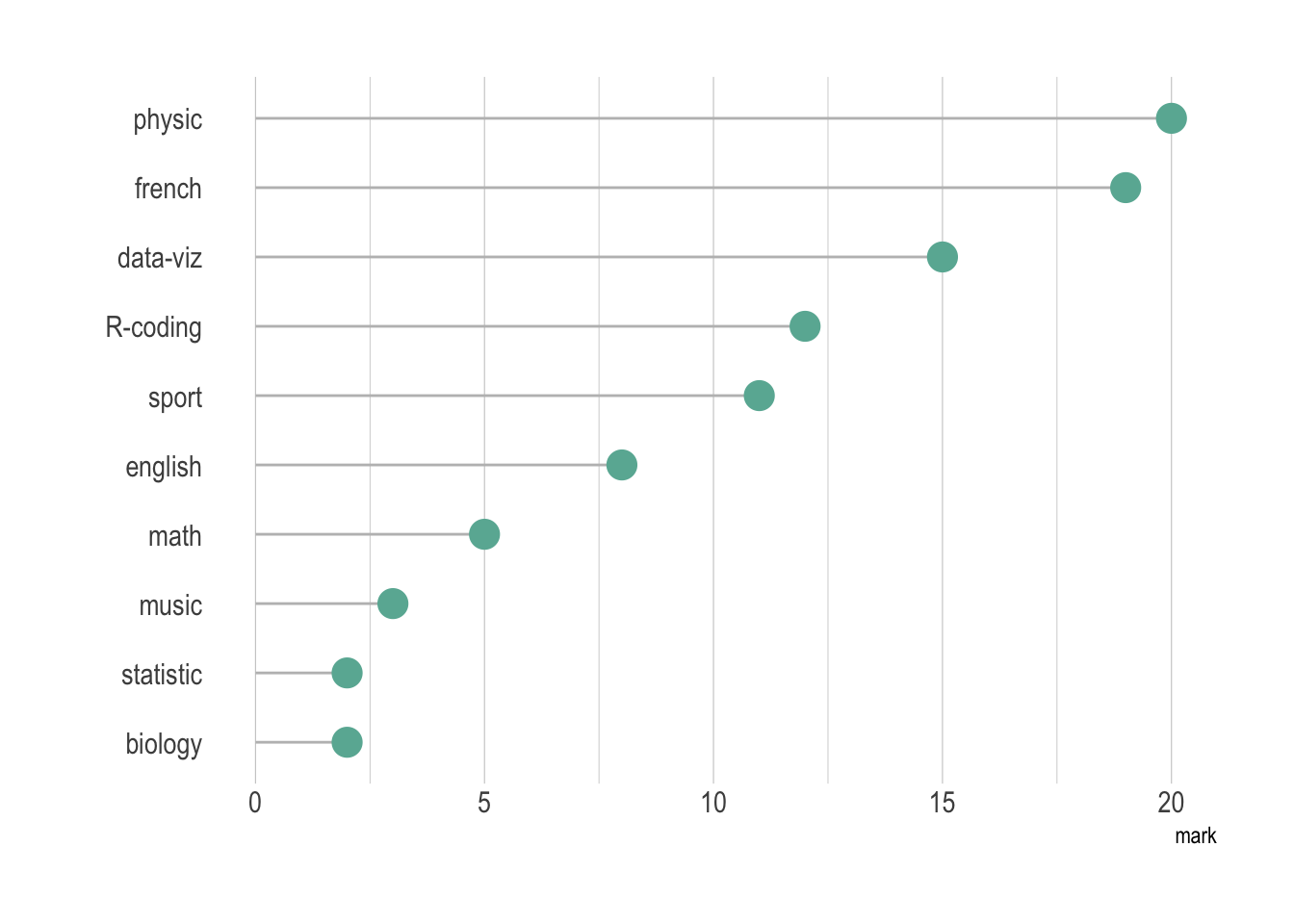
- 圆形布局 = 更难阅读
- 不支持排名
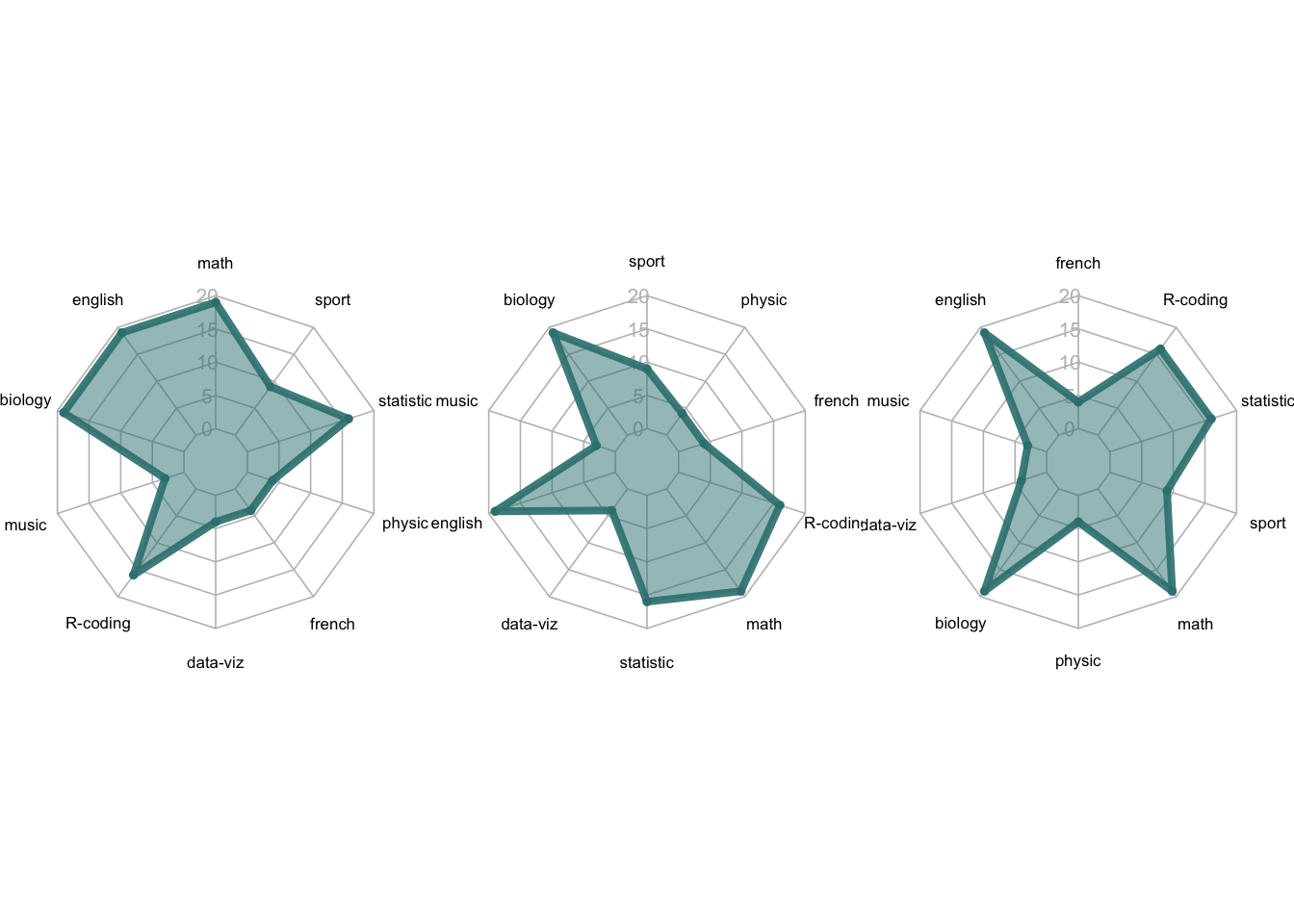
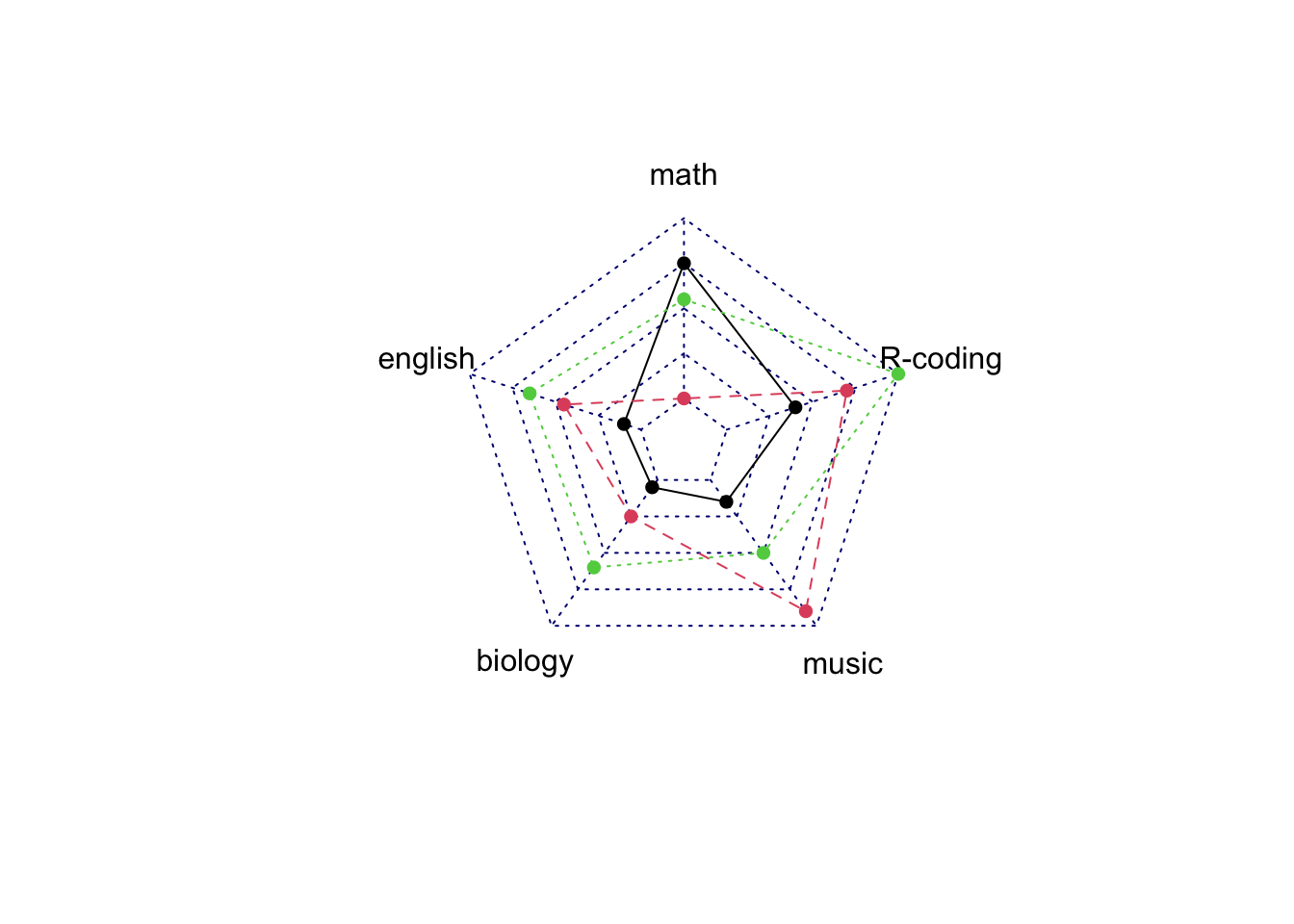
- 类别顺序影响巨大: 同样的数据不同的排序,形状差别巨大
- 刻度不自由: 直观上 各类别的刻度应该是一样的, 设置每个类别的刻度不同, 会导致误解
- 重叠绘图: 过多观测时不好展示
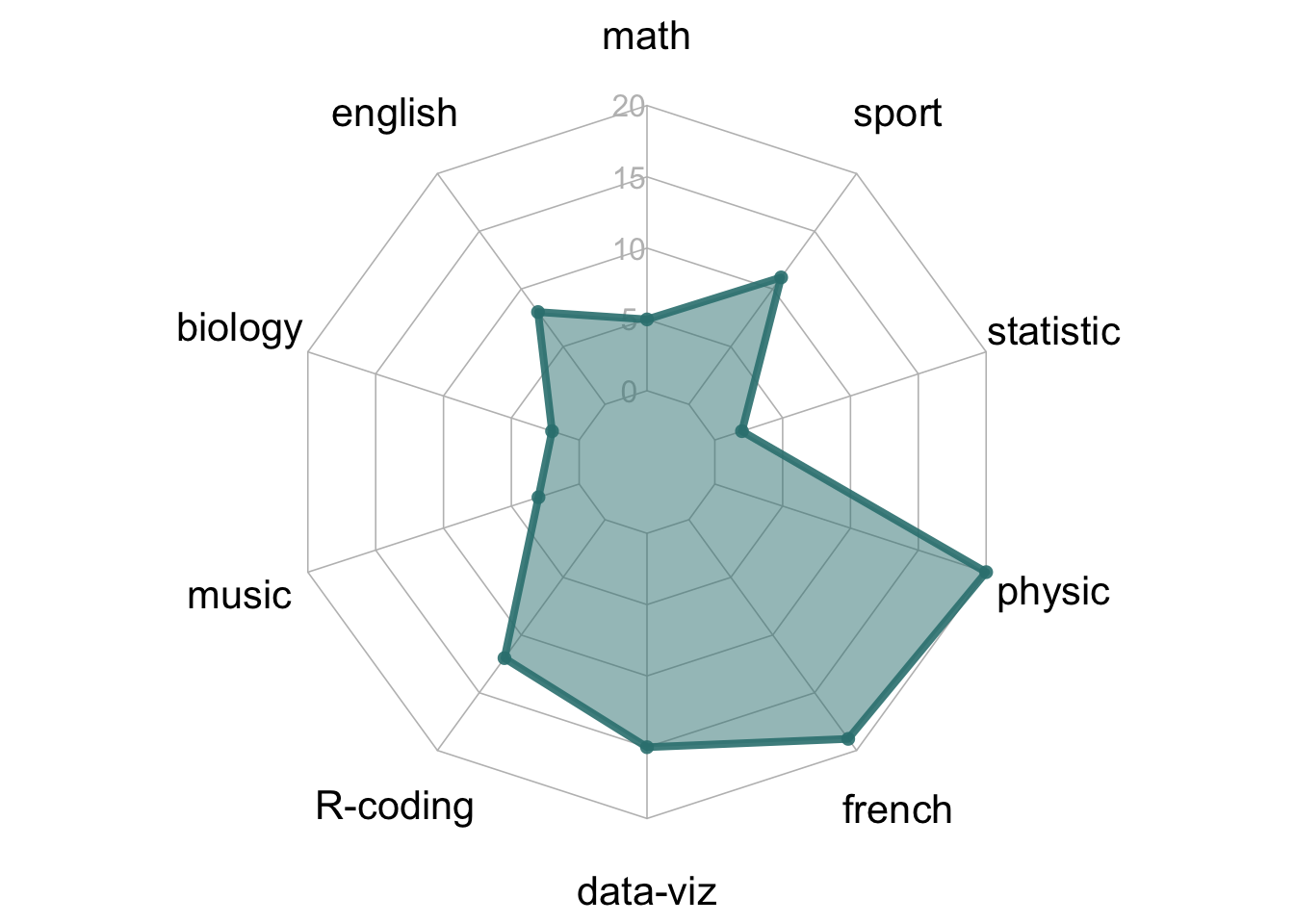
- 过度评估差异: 雷达图中形状的面积也会以平方而非线性的方式增加,看起来差异比实际更显著
```{r}
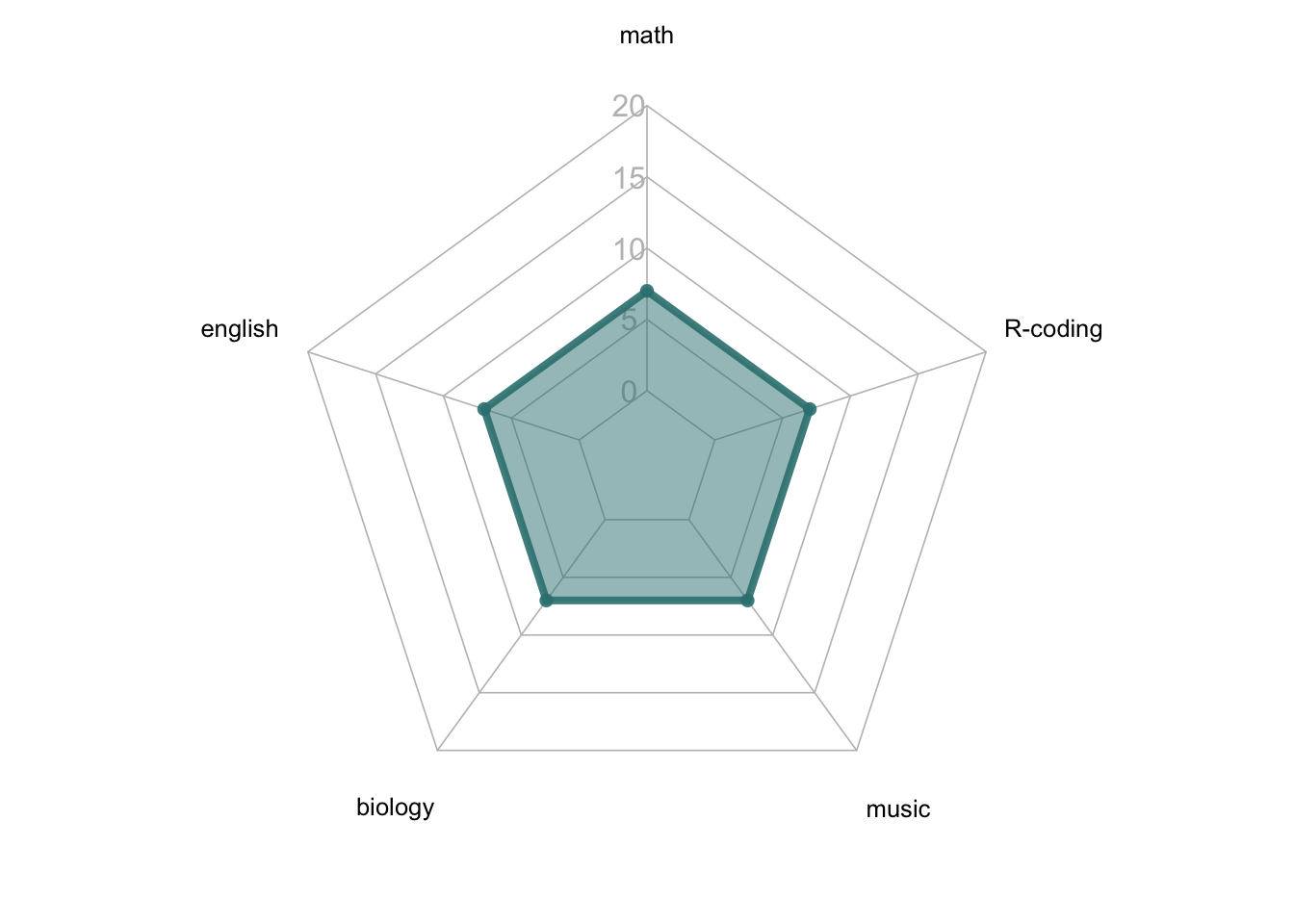
#| fig-cap: "雷达图不如棒棒糖直观"
#| layout-ncol: 2
#| fig-subcap:
#| - 左:雷达图;
#| - 右:棒棒糖图
# 设置随机种子,保证结果可复现
set.seed(1)
# 生成一个包含10个科目的数据框,每个科目随机生成一个2到20之间的整数
data <- as.data.frame(matrix(sample(2:20, 10, replace = TRUE), ncol = 10))
# 设置列名为各个科目
colnames(data) <- c(
"math", # 数学
"english", # 英语
"biology", # 生物
"music", # 音乐
"R-coding", # R编程
"data-viz", # 数据可视化
"french", # 法语
"physic", # 物理
"statistic", # 统计
"sport" # 体育
)
# 为了使用fmsb包绘制雷达图,需要在数据框前面添加最大值和最小值两行
data <- rbind(rep(20, 10), rep(0, 10), data)
# 自定义雷达图
par(mar = c(0, 0, 0, 0)) # 设置画布边距
radarchart(
data, # 输入数据
axistype = 1, # 坐标轴类型
# 自定义多边形
pcol = rgb(0.2, 0.5, 0.5, 0.9), # 多边形边框颜色
pfcol = rgb(0.2, 0.5, 0.5, 0.5), # 多边形填充颜色
plwd = 4, # 多边形边框线宽
# 自定义网格
cglcol = "grey", # 网格线颜色
cglty = 1, # 网格线类型
axislabcol = "grey", # 轴标签颜色
caxislabels = seq(0, 20, 5), # 轴标签内容
cglwd = 0.8, # 网格线宽
# 自定义标签
vlcex = 1.3 # 变量标签字体大小
)
# 条形图:展示同一组数据的分布,更易于比较
data |>
slice(3) |> # 选取第三行(即实际数据,前两行为最大最小值)
t() |> # 转置数据框,方便后续处理
as.data.frame() |> # 转换为数据框
tibble::rownames_to_column() |> # 将行名(科目名)转为一列
arrange(V1) |> # 按分数升序排列
mutate(rowname = factor(rowname, rowname)) |> # 保持原有顺序
ggplot(aes(x = rowname, y = V1)) + # 绘图,x轴为科目,y轴为分数
geom_segment(
aes(x = rowname, xend = rowname, y = 0, yend = V1),
color = "grey" # 绘制灰色线段
) +
geom_point(size = 5, color = "#69b3a2") + # 绘制数据点
coord_flip() + # 翻转坐标轴,横向展示
theme_ipsum() + # 使用hrbrthemes包的主题
theme(
panel.grid.minor.y = element_blank(), # 去除y轴次网格线
panel.grid.major.y = element_blank(), # 去除y轴主网格线
axis.text = element_text(size = 48), # 设置坐标轴文字大小
legend.position = "none" # 不显示图例
) +
ylim(0, 20) + # 设置y轴范围
ylab("mark") + # y轴标签
xlab("") # x轴标签为空
```
```{r}
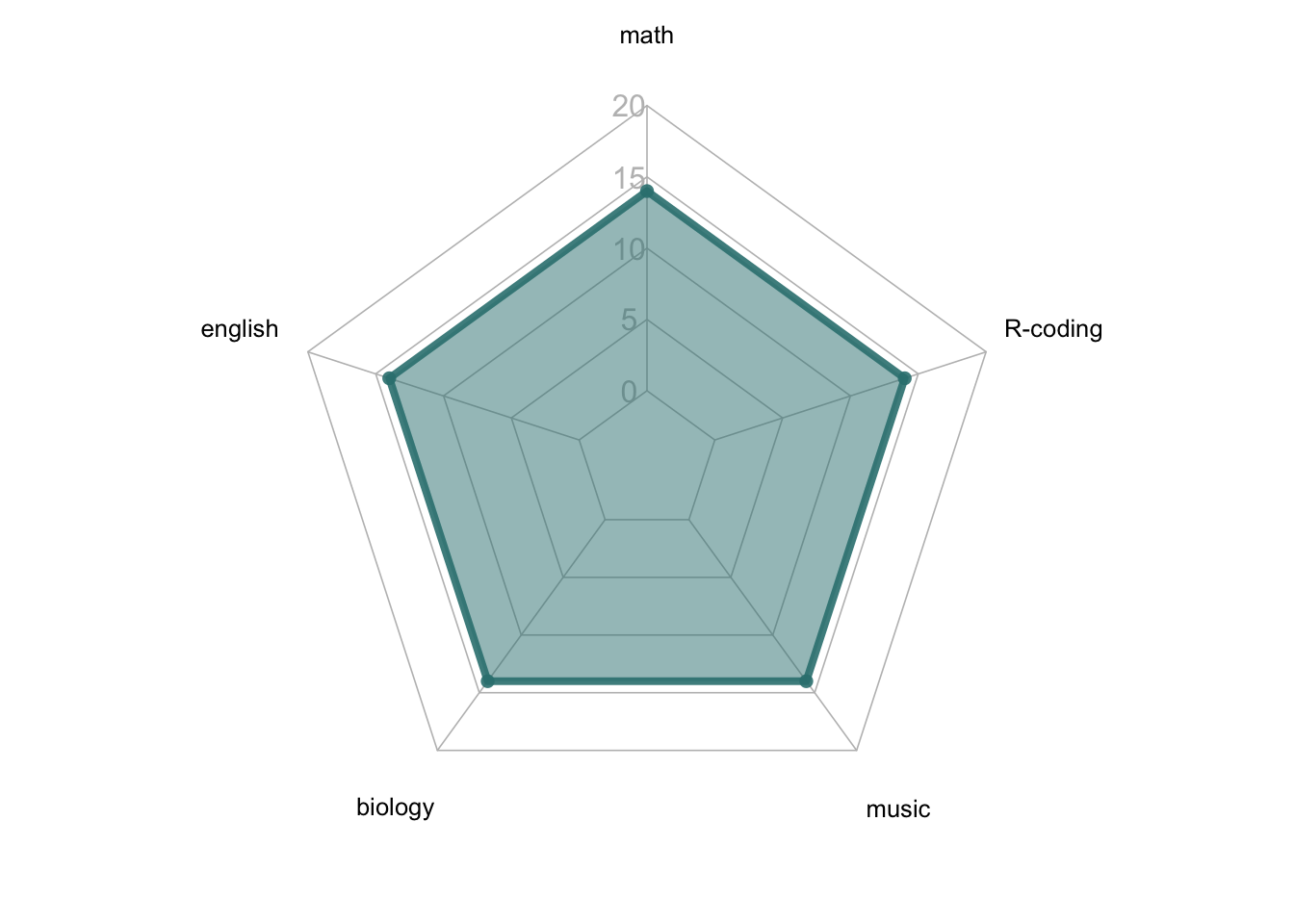
#| fig-cap: "类别顺序影响雷达图形状:同一组数据,不同类别顺序,形状差异巨大"
# 创建数据:Jonathan在高中各科的成绩
set.seed(7)
data <- as.data.frame(matrix(sample(2:20, 10, replace = TRUE), ncol = 10))
colnames(data) <- c(
"math", # 数学
"english", # 英语
"biology", # 生物
"music", # 音乐
"R-coding", # R编程
"data-viz", # 数据可视化
"french", # 法语
"physic", # 物理
"statistic", # 统计
"sport" # 体育
)
# 将前三门科目的成绩设为19,6~8门成绩设为4,突出差异
data[1, 1:3] <- rep(19, 3)
data[1, 6:8] <- rep(4, 3)
# 按fmsb包要求,前两行为最大值和最小值
data <- rbind(rep(20, 10), rep(0, 10), data)
# 改变类别顺序,生成两组不同顺序的数据
data2 <- data[, sample(1:10, 10, replace = FALSE)]
data3 <- data[, sample(1:10, 10, replace = FALSE)]
# 自定义雷达图,展示同一组数据在不同类别顺序下的形状变化
par(mar = c(0, 0, 0, 0)) # 设置画布边距为0
par(mfrow = c(1, 3)) # 一行三列布局,便于对比
# 绘制第一组类别顺序的雷达图
radarchart(
data, # 输入数据
axistype = 1, # 坐标轴类型
pcol = rgb(0.2, 0.5, 0.5, 0.9), # 多边形边框颜色
pfcol = rgb(0.2, 0.5, 0.5, 0.5), # 多边形填充颜色
plwd = 4, # 多边形边框线宽
cglcol = "grey", # 网格线颜色
cglty = 1, # 网格线类型
axislabcol = "grey", # 轴标签颜色
caxislabels = seq(0, 20, 5),# 轴标签内容
cglwd = 0.8, # 网格线宽
vlcex = 0.8 # 变量标签字体大小
)
# 绘制第二组类别顺序的雷达图
radarchart(
data2, # 输入数据(类别顺序已打乱)
axistype = 1,
pcol = rgb(0.2, 0.5, 0.5, 0.9),
pfcol = rgb(0.2, 0.5, 0.5, 0.5),
plwd = 4,
cglcol = "grey",
cglty = 1,
axislabcol = "grey",
caxislabels = seq(0, 20, 5),
cglwd = 0.8,
vlcex = 0.8
)
# 绘制第三组类别顺序的雷达图
radarchart(
data3, # 输入数据(类别顺序再次打乱)
axistype = 1,
pcol = rgb(0.2, 0.5, 0.5, 0.9),
pfcol = rgb(0.2, 0.5, 0.5, 0.5),
plwd = 4,
cglcol = "grey",
cglty = 1,
axislabcol = "grey",
caxislabels = seq(0, 20, 5),
cglwd = 0.8,
vlcex = 0.8
)
par(mfrow = c(1, 1)) # 重置布局
```
```{r}
#| fig-cap: "雷达图过度评估了差距"
#| layout-ncol: 2
#| fig-subcap:
#| - 左:所有科目分数均为7;
#| - 右:所有科目分数均为14。
# 生成一个包含5个科目的数据框,每个科目分数均为7
data <- as.data.frame(matrix(c(7, 7, 7, 7, 7), ncol = 5))
# 设置列名为各个科目
colnames(data) <- c("math", "english", "biology", "music", "R-coding")
# fmsb包要求数据框前两行为最大值和最小值,这里最大值为20,最小值为0
data <- rbind(rep(20, 5), rep(0, 5), data)
# 复制一份数据,作为第二组数据
data2 <- data
# 修改第三行(即实际数据),将分数全部设为14
data2[3, ] <- rep(14, 5)
# 设置画布边距为0,避免图形被裁剪
par(mar = rep(0, 4))
# 绘制第一组数据的雷达图
radarchart(
data, # 输入数据
axistype = 1, # 坐标轴类型
pcol = rgb(0.2, 0.5, 0.5, 0.9), # 多边形边框颜色
pfcol = rgb(0.2, 0.5, 0.5, 0.5), # 多边形填充颜色
plwd = 4, # 多边形边框线宽
cglcol = "grey", # 网格线颜色
cglty = 1, # 网格线类型
axislabcol = "grey", # 轴标签颜色
caxislabels = seq(0, 20, 5), # 轴标签内容
cglwd = 0.8, # 网格线宽
vlcex = 0.8 # 变量标签字体大小
)
# 绘制第二组数据的雷达图
radarchart(
data2, # 输入数据
axistype = 1, # 坐标轴类型
pcol = rgb(0.2, 0.5, 0.5, 0.9), # 多边形边框颜色
pfcol = rgb(0.2, 0.5, 0.5, 0.5), # 多边形填充颜色
plwd = 4, # 多边形边框线宽
cglcol = "grey", # 网格线颜色
cglty = 1, # 网格线类型
axislabcol = "grey", # 轴标签颜色
caxislabels = seq(0, 20, 5), # 轴标签内容
cglwd = 0.8, # 网格线宽
vlcex = 0.8 # 变量标签字体大小
)
```
## 改进
如果刻度相同, 可以使用条形图、棒棒糖图(吸管图)代替雷达图, 并进行排序
```{r}
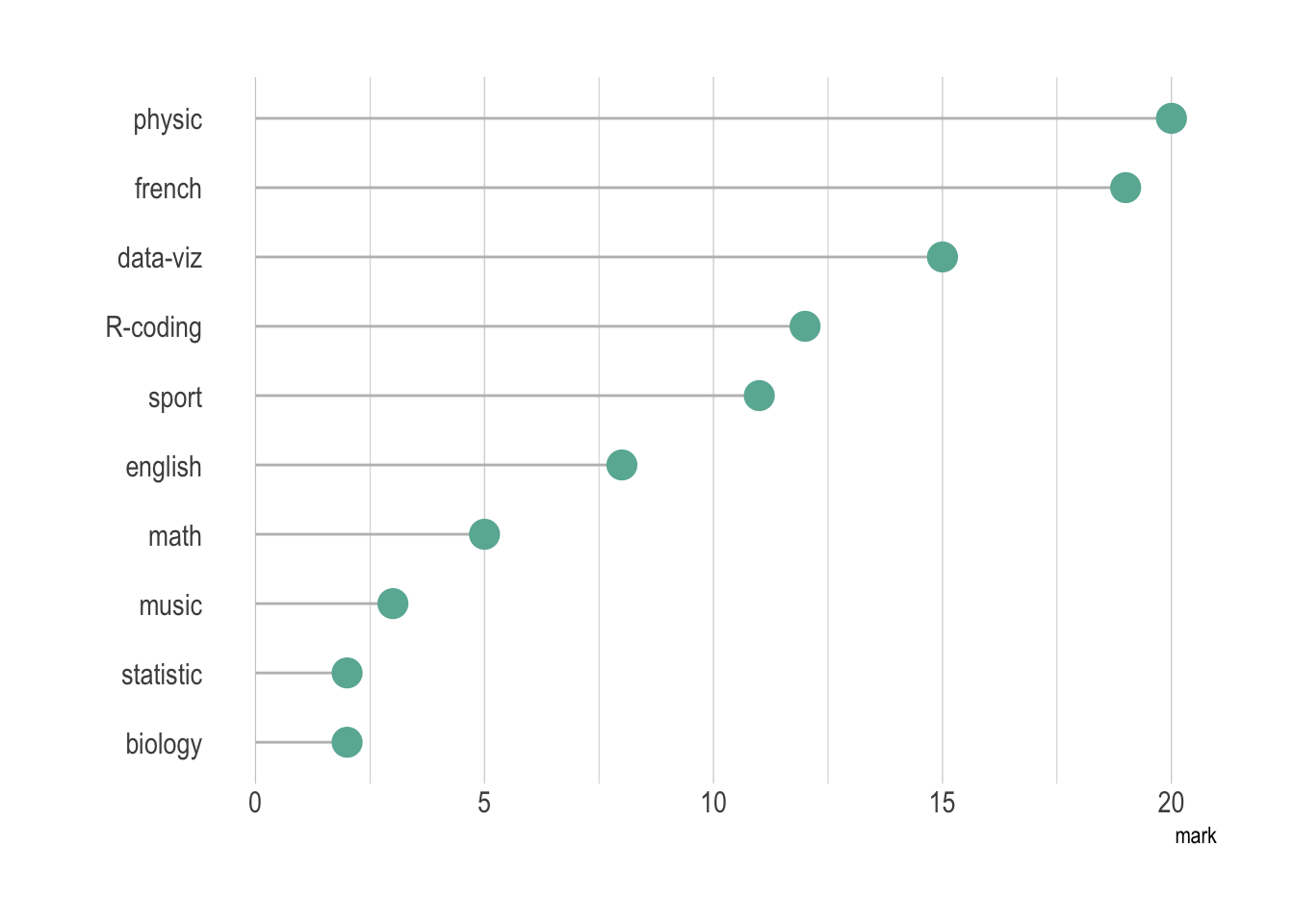
#| fig-cap: "棒棒糖图:同一组数据的分数分布,更易于比较"
# 设置随机种子,保证结果可复现
set.seed(1)
# 生成一个包含10个科目的数据框,每个科目随机生成一个2到20之间的整数
data <- as.data.frame(matrix(sample(2:20, 10, replace = TRUE), ncol = 10))
# 设置列名为各个科目
colnames(data) <- c(
"math", # 数学
"english", # 英语
"biology", # 生物
"music", # 音乐
"R-coding", # R编程
"data-viz", # 数据可视化
"french", # 法语
"physic", # 物理
"statistic", # 统计
"sport" # 体育
)
# 为了与雷达图数据结构一致,前两行为最大值和最小值
data <- rbind(rep(20, 10), rep(0, 10), data)
# 棒棒糖图:展示同一组数据的分布,更易于比较
data |>
slice(3) |> # 选取第三行(即实际数据,前两行为最大最小值)
t() |> # 转置数据框,方便后续处理
as.data.frame() |> # 转换为数据框
tibble::rownames_to_column() |> # 将行名(科目名)转为一列
arrange(V1) |> # 按分数升序排列
mutate(rowname = factor(rowname, rowname)) |> # 保持原有顺序
ggplot(aes(x = rowname, y = V1)) + # 绘图,x轴为科目,y轴为分数
geom_segment(
aes(x = rowname, xend = rowname, y = 0, yend = V1),
color = "grey" # 绘制灰色线段
) +
geom_point(size = 5, color = "#69b3a2") + # 绘制数据点
coord_flip() + # 翻转坐标轴,横向展示
theme_ipsum() + # 使用hrbrthemes包的主题
theme(
panel.grid.minor.y = element_blank(), # 去除y轴次网格线
panel.grid.major.y = element_blank(), # 去除y轴主网格线
axis.text = element_text(size = 48), # 设置坐标轴文字大小
legend.position = "none" # 不显示图例
) +
ylim(0, 20) + # 设置y轴范围
ylab("mark") + # y轴标签
xlab("") # x轴标签为空
```
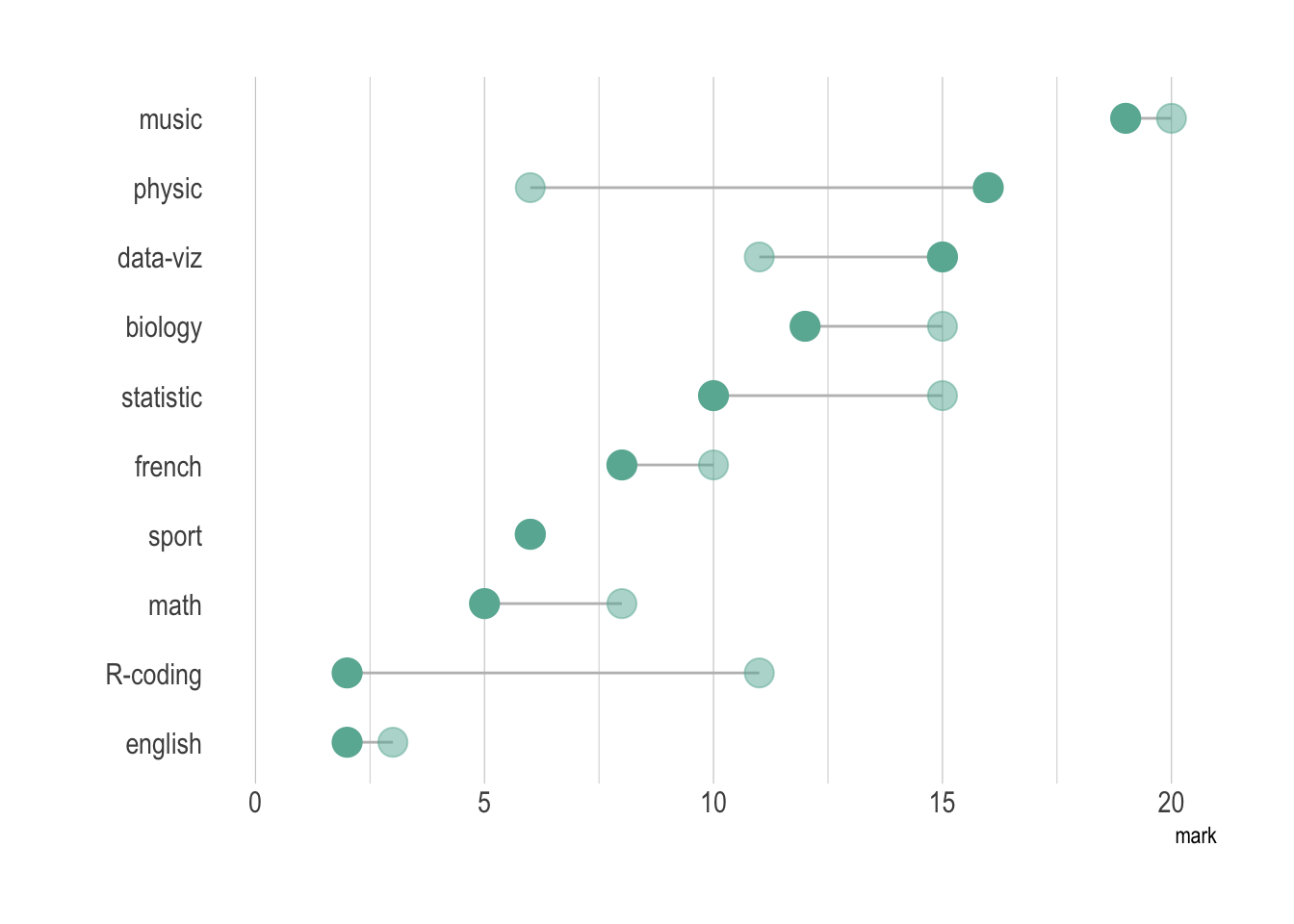
两个观测进行对比(哑铃图), 设置颜色或透明度来区分两组:
```{r}
#| fig-cap: "哑铃图:对比两组观测在各科目的分数差异"
# 设置随机种子,保证结果可复现
set.seed(1)
# 生成一个包含10个科目的数据框,每个科目随机生成一个2到20之间的整数,共两组观测
data <- as.data.frame(matrix(sample(2:20, 20, replace = TRUE), ncol = 10))
# 设置列名为各个科目
colnames(data) <- c(
"math", # 数学
"english", # 英语
"biology", # 生物
"music", # 音乐
"R-coding", # R编程
"data-viz", # 数据可视化
"french", # 法语
"physic", # 物理
"statistic", # 统计
"sport" # 体育
)
# 为了与雷达图数据结构一致,前两行为最大值和最小值
data <- rbind(rep(20, 10), rep(0, 10), data)
# 哑铃图:对比两组观测在各科目的分数差异
data |>
slice(c(3, 4)) |> # 选取第三、四行(即两组实际观测数据)
t() |> # 转置数据框,方便后续处理
as.data.frame() |> # 转换为数据框
tibble::rownames_to_column() |> # 将行名(科目名)转为一列
arrange(V1) |> # 按第一组分数升序排列
mutate(rowname = factor(rowname, rowname)) |> # 保持原有顺序
ggplot(aes(x = rowname, y = V1)) + # 绘图,x轴为科目,y轴为第一组分数
geom_segment(
aes(x = rowname, xend = rowname, y = V2, yend = V1),
color = "grey" # 绘制两组分数之间的线段
) +
geom_point(size = 5, color = "#69b3a2") + # 绘制第一组分数的数据点
geom_point(aes(y = V2), size = 5, color = "#69b3a2", alpha = 0.5) + # 绘制第二组分数的数据点(透明)
coord_flip() + # 翻转坐标轴,横向展示
theme_ipsum() + # 使用hrbrthemes包的主题
theme(
panel.grid.minor.y = element_blank(), # 去除y轴次网格线
panel.grid.major.y = element_blank(), # 去除y轴主网格线
axis.text = element_text(size = 48) # 设置坐标轴文字大小
) +
ylim(0, 20) + # 设置y轴范围
ylab("mark") + # y轴标签
xlab("") # x轴标签为空
```
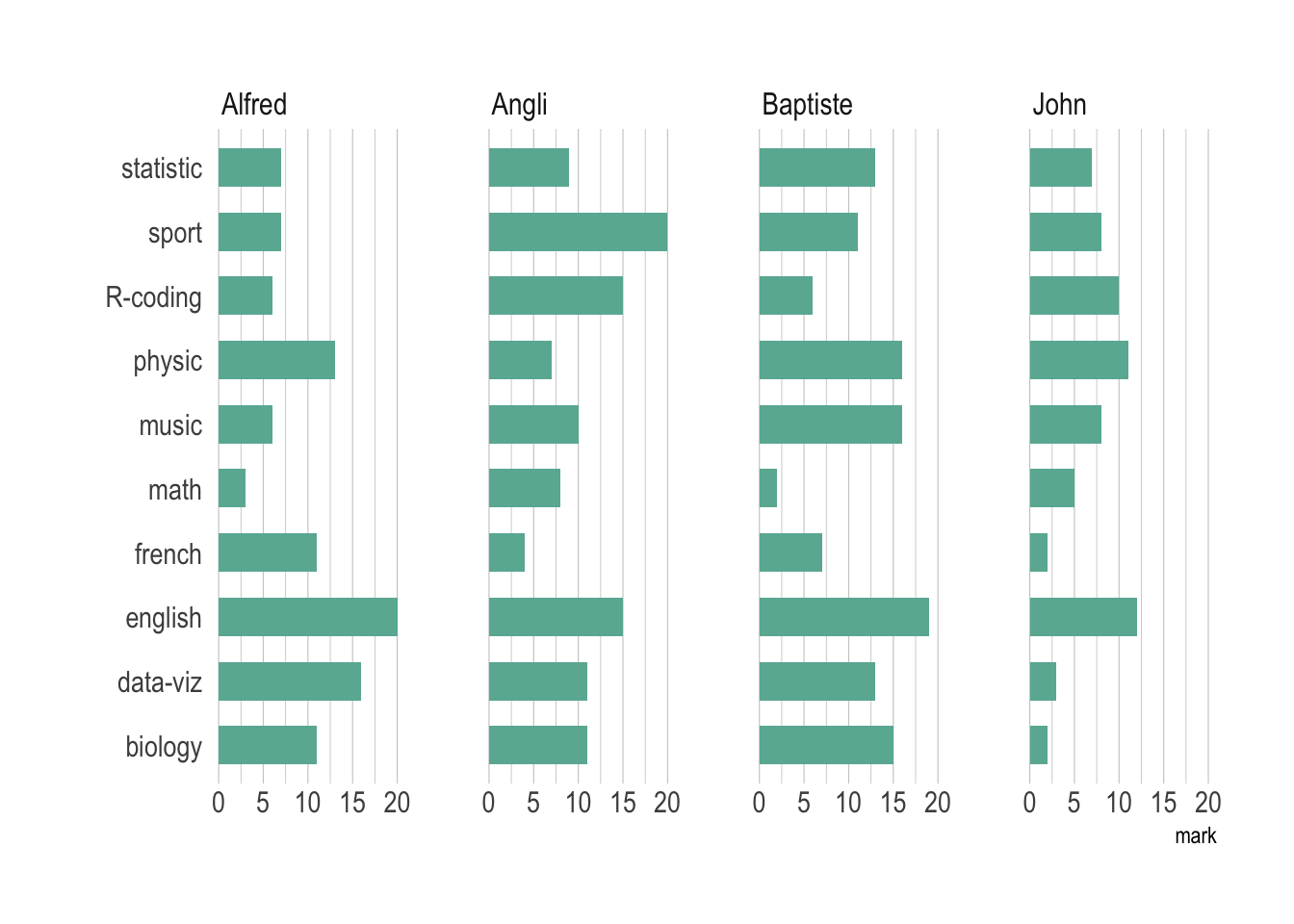
观测很多考虑分面:
```{r}
#| fig-cap: "分面棒棒糖图:多位同学各科成绩分布对比"
# 设置随机种子,保证结果可复现
set.seed(1)
# 生成一个包含4位同学、10个科目的数据框,每个科目随机生成一个2到20之间的整数
data <- as.data.frame(matrix(sample(2:20, 40, replace = TRUE), ncol = 10))
# 设置列名为各个科目
colnames(data) <- c(
"math", # 数学
"english", # 英语
"biology", # 生物
"music", # 音乐
"R-coding", # R编程
"data-viz", # 数据可视化
"french", # 法语
"physic", # 物理
"statistic", # 统计
"sport" # 体育
)
# 为了使用fmsb包绘制雷达图,需要在数据框前面添加最大值和最小值两行
data <- rbind(rep(20, 10), rep(0, 10), data)
# 设置行名为4位同学
rownames(data) <- c("-", "--", "John", "Angli", "Baptiste", "Alfred")
# 数据整理:选取4位同学的数据,转置后整理为长格式,便于ggplot分面绘图
data |>
slice(3:6) |> # 选取第3到第6行(4位同学的成绩)
t() |> # 转置数据框,行变为科目,列为同学
as.data.frame() |> # 转换为数据框
tibble::rownames_to_column() |> # 将行名(科目名)转为一列
tidyr::gather(key = name, value = mark, -rowname) |> # 宽数据转为长数据
mutate(
# 重编码同学姓名,便于分面标签美观
name = dplyr::recode(
name,
V1 = "John",
V2 = "Angli",
V3 = "Baptiste",
V4 = "Alfred"
),
# 保持科目顺序
# rowname = factor(rowname, rowname)
) |>
# 绘图:分面棒棒糖图
ggplot(aes(x = rowname, y = mark)) +
geom_bar(stat = "identity", fill = "#69b3a2", width = 0.6) + # 绘制条形
coord_flip() + # 翻转坐标轴,横向展示
theme_ipsum() + # 使用hrbrthemes包的主题
theme(
panel.grid.minor.y = element_blank(), # 去除y轴次网格线
panel.grid.major.y = element_blank(), # 去除y轴主网格线
axis.text = element_text(size = 48) # 设置坐标轴文字大小
) +
ylim(0, 20) + # 设置y轴范围
ylab("mark") + # y轴标签
xlab("") + # x轴标签为空
facet_wrap(~name, ncol = 4) # 按同学分面展示,每行4个分面
```
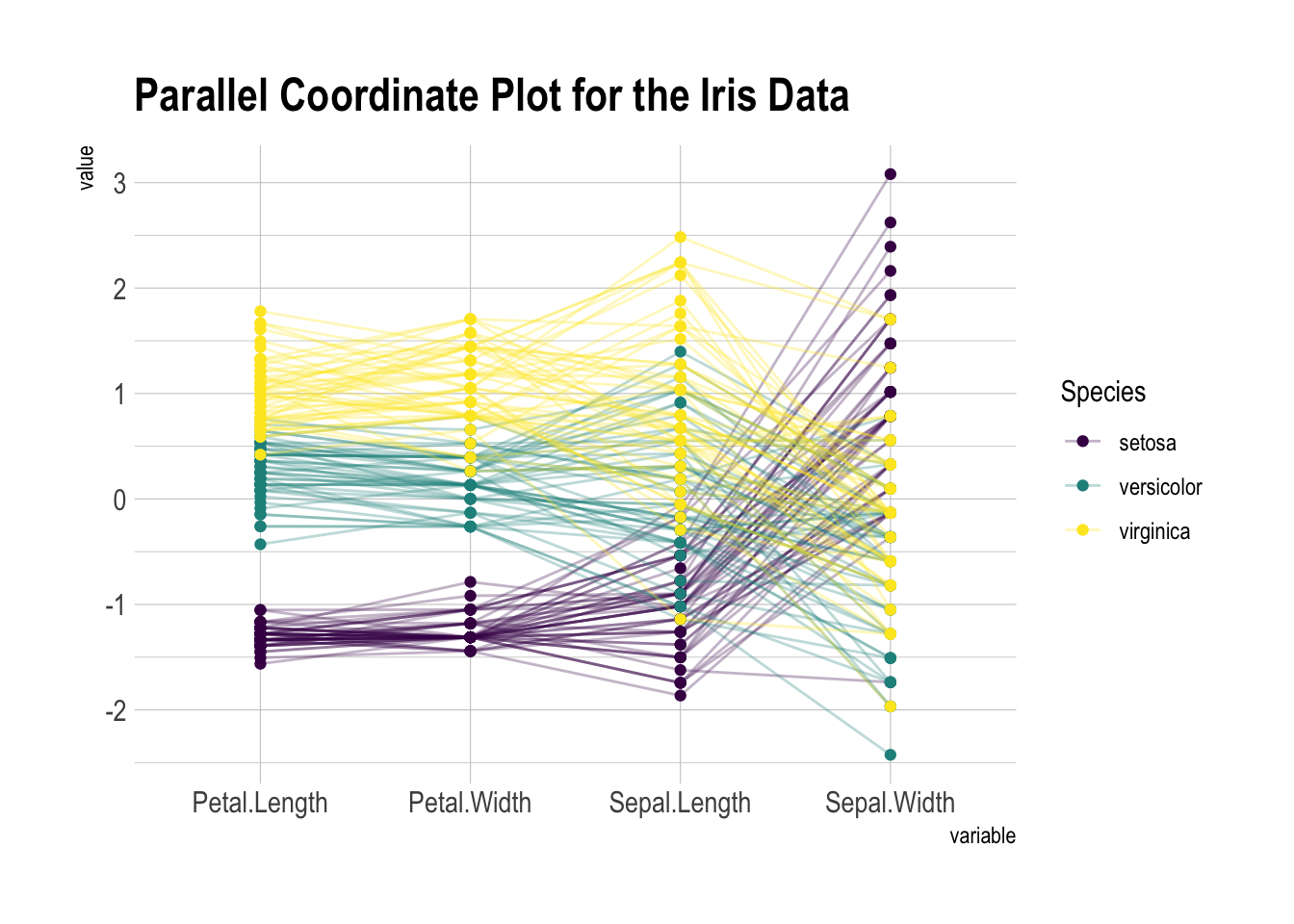
多系列且不同刻度:
```{r}
#| fig-cap: "鸢尾花数据集的平行坐标图:不同种类的花在各特征上的分布对比"
# 加载GGally包用于平行坐标图
library(GGally)
# 加载示例数据集iris
data <- iris
# 使用ggparcoord绘制平行坐标图
data |>
ggparcoord(
columns = 1:4, # 选择前4列(花萼长度、花萼宽度、花瓣长度、花瓣宽度)
groupColumn = 5, # 按第5列(Species,花的种类)分组上色
order = "anyClass", # 变量顺序自动排列
showPoints = TRUE, # 显示每个观测点
title = "Parallel Coordinate Plot for the Iris Data", # 图标题
alphaLines = 0.3 # 线条透明度
) +
scale_color_viridis(discrete = TRUE) + # 使用viridis配色方案
theme_ipsum() # 使用hrbrthemes包的美化主题
```
## 单组
### 基本
```{r}
#| fig-cap: "基本雷达图"
# 生成一个包含10个科目的数据框,每个科目随机生成一个2到20之间的整数
data <- matrix(sample(2:20, 10, replace = TRUE), ncol = 10) |>
as.data.frame()
# 设置列名为各个科目
colnames(data) <- c(
"math", # 数学
"english", # 英语
"biology", # 生物
"music", # 音乐
"R-coding", # R编程
"data-viz", # 数据可视化
"french", # 法语
"physic", # 物理
"statistic", # 统计
"sport" # 体育
)
# 为了使用fmsb包绘制雷达图,需要在数据框前面添加最大值和最小值两行
data <- rbind(rep(20, 10), rep(0, 10), data)
# 检查数据格式是否正确
# head(data)
# 绘制默认的雷达图
radarchart(data)
```
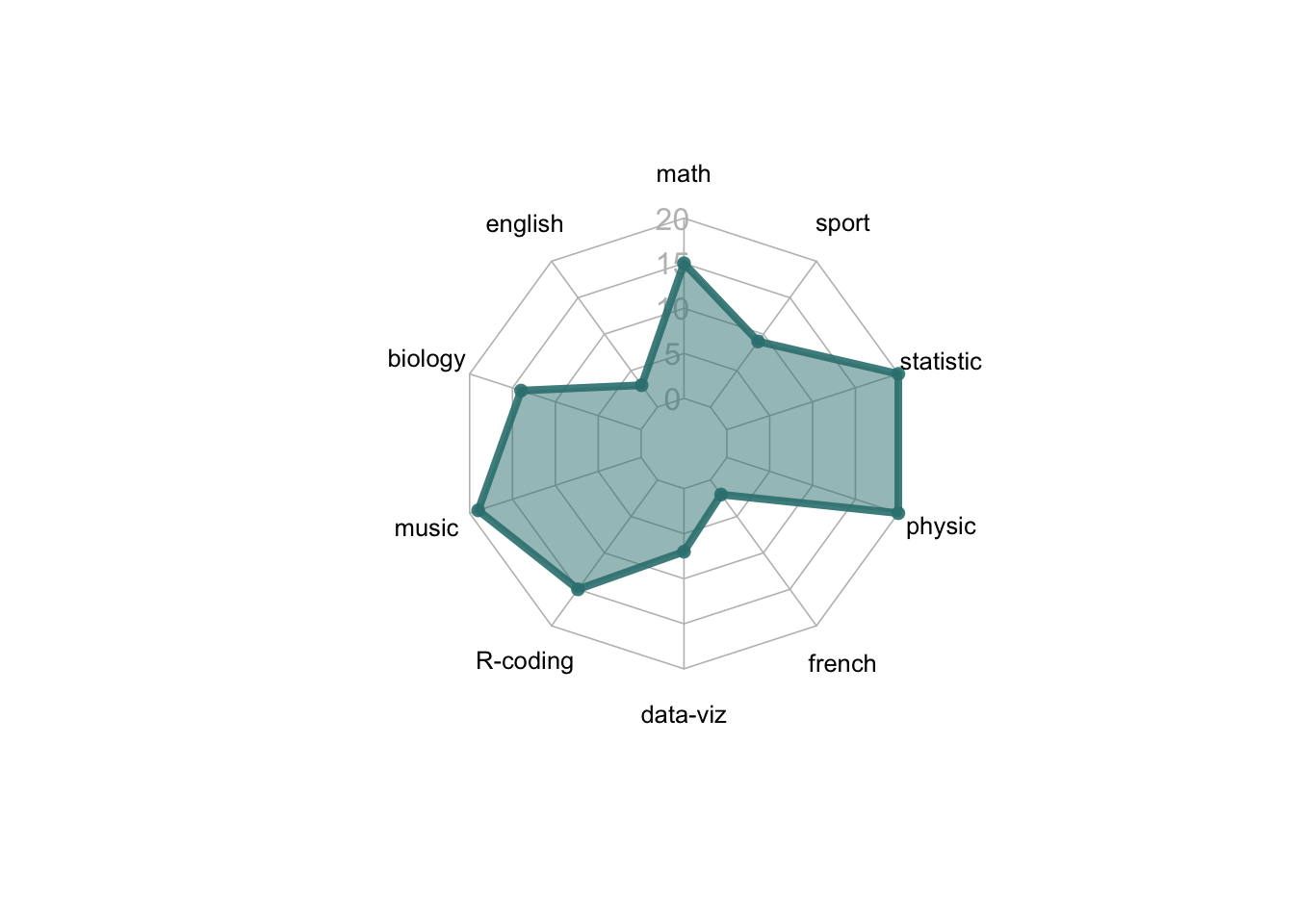
### 定制
```{r}
#| fig-cap: "定制雷达图:自定义多边形颜色、线宽、网格和标签"
# 使用 radarchart 绘制定制雷达图
radarchart(
data, # 输入数据
axistype = 1, # 坐标轴类型
# 自定义多边形
pcol = rgb(0.2, 0.5, 0.5, 0.9), # 多边形边框颜色
pfcol = rgb(0.2, 0.5, 0.5, 0.5), # 多边形填充颜色
plwd = 4, # 多边形边框线宽
# 自定义网格
cglcol = "grey", # 网格线颜色
cglty = 1, # 网格线类型
axislabcol = "grey", # 轴标签颜色
caxislabels = seq(0, 20, 5), # 轴标签内容
cglwd = 0.8, # 网格线宽
# 自定义标签
vlcex = 0.8 # 变量标签字体大小
)
```
## 多组
### 基本
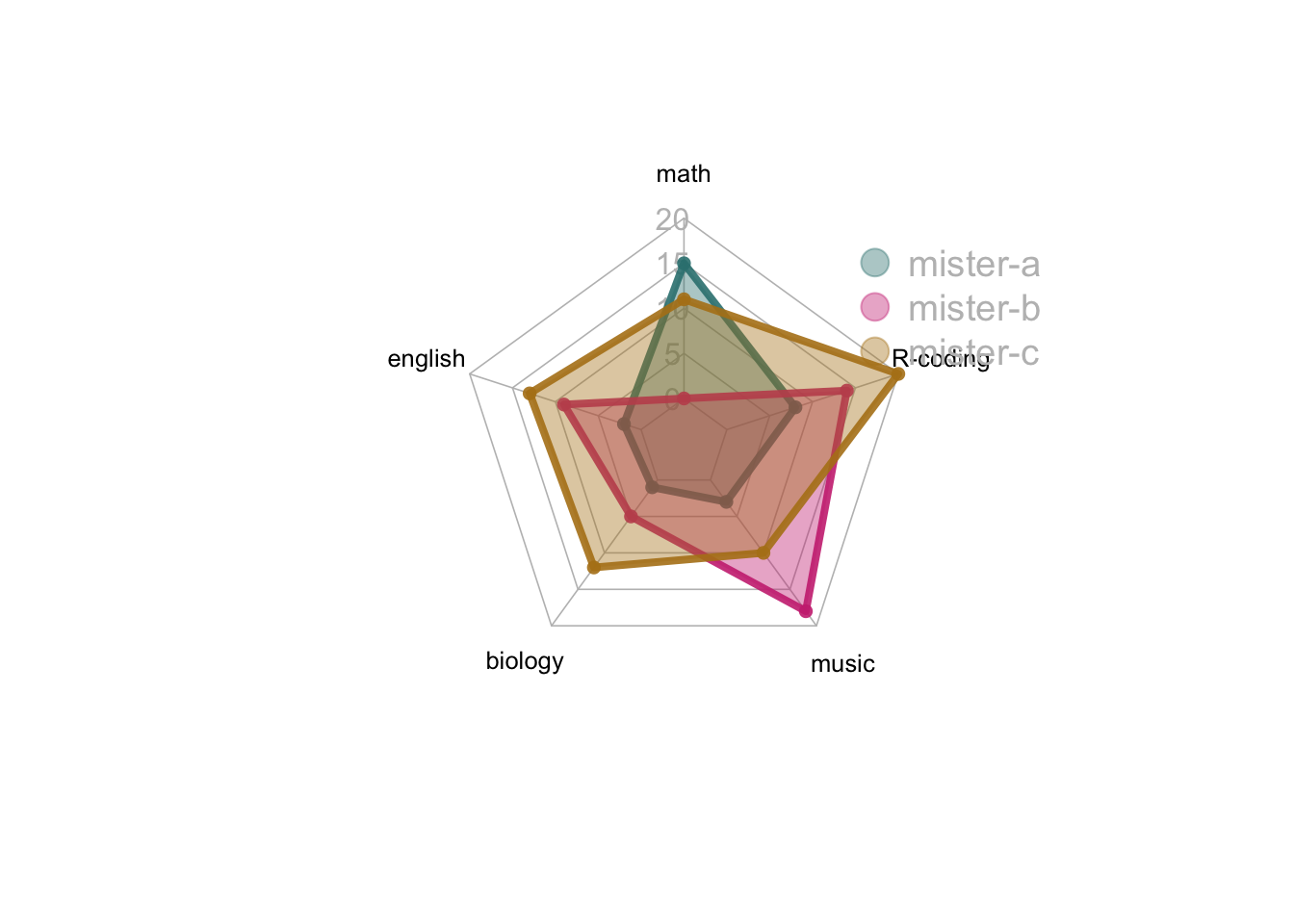
```{r}
#| fig-cap: "多组雷达图:展示三位同学在五个科目的表现"
# 设置随机种子,保证结果可复现
set.seed(99)
# 生成一个3行5列的数据框,表示3位同学在5个科目的分数(0~20之间不重复的整数)
data <- matrix(sample(0:20, 15, replace = FALSE), ncol = 5) |>
as.data.frame()
# 设置列名为各个科目
colnames(data) <- c("math", "english", "biology", "music", "R-coding")
# 设置行名为三位同学
rownames(data) <- paste("mister", letters[1:3], sep = "-")
# fmsb包要求数据框前两行为最大值和最小值
data <- rbind(rep(20, 5), rep(0, 5), data)
# 绘制多组雷达图,展示三位同学的成绩分布
radarchart(data)
```
### 定制
```{r}
#| fig-cap: "定制多组雷达图:不同颜色区分三位同学的成绩,并添加图例"
# 定义多边形边框颜色向量
colors_border <- c(
rgb(0.2, 0.5, 0.5, 0.9), # 第一位同学的边框颜色
rgb(0.8, 0.2, 0.5, 0.9), # 第二位同学的边框颜色
rgb(0.7, 0.5, 0.1, 0.9) # 第三位同学的边框颜色
)
# 定义多边形填充颜色向量
colors_in <- c(
rgb(0.2, 0.5, 0.5, 0.4), # 第一位同学的填充颜色
rgb(0.8, 0.2, 0.5, 0.4), # 第二位同学的填充颜色
rgb(0.7, 0.5, 0.1, 0.4) # 第三位同学的填充颜色
)
# 绘制定制多组雷达图
radarchart(
data, # 输入数据
axistype = 1, # 坐标轴类型
# 自定义多边形
pcol = colors_border, # 多边形边框颜色
pfcol = colors_in, # 多边形填充颜色
plwd = 4, # 多边形边框线宽
plty = 1, # 多边形线型
# 自定义网格
cglcol = "grey", # 网格线颜色
cglty = 1, # 网格线类型
axislabcol = "grey", # 轴标签颜色
caxislabels = seq(0, 20, 5), # 轴标签内容
cglwd = 0.8, # 网格线宽
# 自定义标签
vlcex = 0.8 # 变量标签字体大小
)
# 添加图例,标注每位同学对应的颜色
legend(
x = 0.7, # 图例x坐标
y = 1, # 图例y坐标
legend = rownames(data[-c(1, 2), ]), # 图例标签(去除最大最小值行)
bty = "n", # 无边框
pch = 20, # 图例点类型
col = colors_in, # 图例点颜色
text.col = "grey", # 图例文字颜色
cex = 1.2, # 图例字体大小
pt.cex = 3 # 图例点大小
)
```
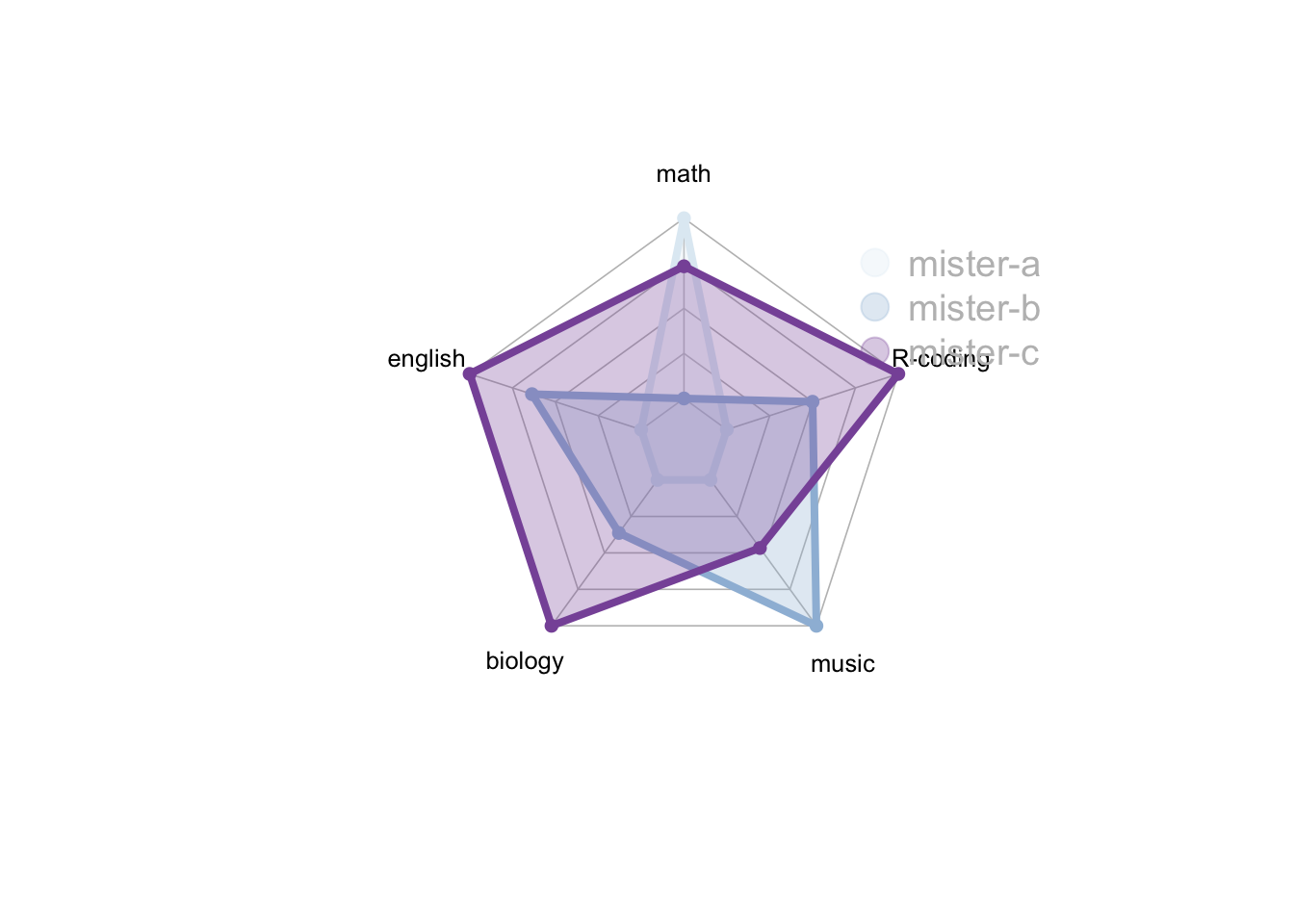
### 坐标轴
如果没有输入坐标轴最大值和最小值, 则会自动计算.
```{r}
#| fig-cap: "自动计算坐标轴范围的雷达图:不手动输入最大最小值"
# 设置随机种子,保证结果可复现
set.seed(99)
# 生成一个3行5列的数据框,表示3位同学在5个科目的分数(0~20之间不重复的整数)
data <- matrix(sample(0:20, 15, replace = FALSE), ncol = 5) |>
as.data.frame()
# 设置列名为各个科目
colnames(data) <- c("math", "english", "biology", "music", "R-coding")
# 设置行名为三位同学
rownames(data) <- paste("mister", letters[1:3], sep = "-")
# 生成配色方案
coul <- brewer.pal(3, "BuPu") # 选取3种颜色
colors_border <- coul # 多边形边框颜色
colors_in <- alpha(coul, 0.3) # 多边形填充颜色,带透明度
# 不添加最大最小值行,radarchart会自动根据数据计算坐标轴范围
radarchart(
data, # 输入数据(不含最大最小值行)
axistype = 0, # 坐标轴类型
maxmin = FALSE, # 不手动指定最大最小值,自动计算
# 自定义多边形
pcol = colors_border, # 多边形边框颜色
pfcol = colors_in, # 多边形填充颜色
plwd = 4, # 多边形边框线宽
plty = 1, # 多边形线型
# 自定义网格
cglcol = "grey", # 网格线颜色
cglty = 1, # 网格线类型
axislabcol = "black", # 轴标签颜色
cglwd = 0.8, # 网格线宽
# 自定义标签
vlcex = 0.8 # 变量标签字体大小
)
# 添加图例,标注每位同学对应的颜色
legend(
x = 0.7, # 图例x坐标
y = 1, # 图例y坐标
legend = rownames(data), # 图例标签
bty = "n", # 无边框
pch = 20, # 图例点类型
col = colors_in, # 图例点颜色
text.col = "grey", # 图例文字颜色
cex = 1.2, # 图例字体大小
pt.cex = 3 # 图例点大小
)
```
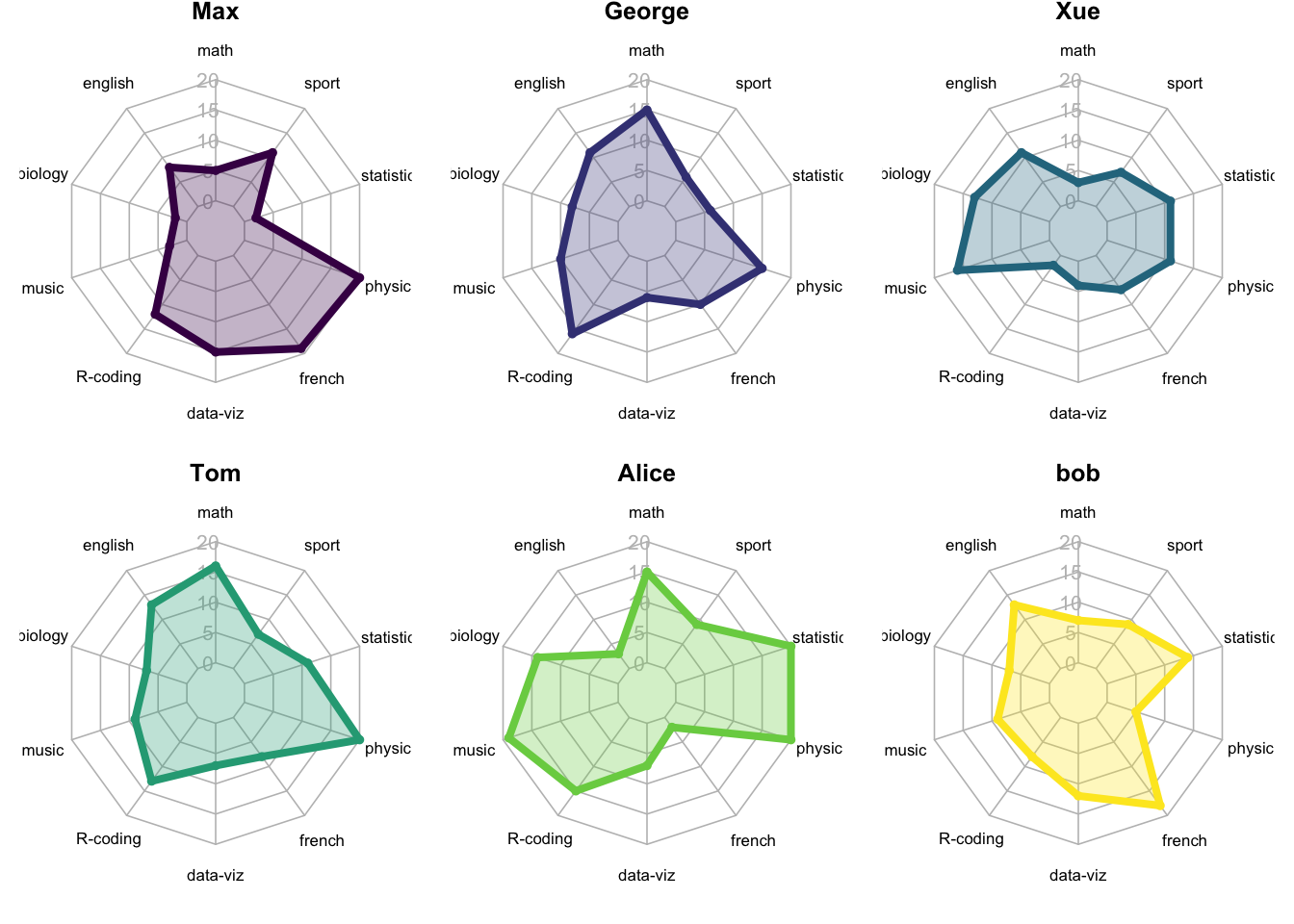
## 超多组
不建议放到一个图中, 但可以分面展示(不是ggplot 分面语法):
```{r}
#| fig-cap: "超多组雷达图:6位同学各自成绩的雷达图分面展示"
# 设置随机种子,保证结果可复现
set.seed(1)
# 生成一个6行10列的数据框,表示6位同学在10个科目的分数(2~20之间可重复)
data <- matrix(
sample(2:20, 60, replace = TRUE), # 随机生成60个2~20之间的整数
ncol = 10, # 每行10个科目
byrow = TRUE # 按行填充
) |>
as.data.frame() # 转换为数据框
# 设置列名为各个科目
colnames(data) <- c(
"math", # 数学
"english", # 英语
"biology", # 生物
"music", # 音乐
"R-coding", # R编程
"data-viz", # 数据可视化
"french", # 法语
"physic", # 物理
"statistic", # 统计
"sport" # 体育
)
# fmsb包要求数据框前两行为最大值和最小值
data <- rbind(rep(20, 10), rep(0, 10), data)
# 生成配色方案,6种颜色
colors_border <- colormap(colormap = colormaps$viridis, nshades = 6, alpha = 1)
colors_in <- colormap(colormap = colormaps$viridis, nshades = 6, alpha = 0.3)
# 设置每个子图的标题
mytitle <- c("Max", "George", "Xue", "Tom", "Alice", "bob")
# 设置画布边距
par(mar = rep(0.8, 4))
# 将画布分为2行3列,准备绘制6个子图
par(mfrow = c(2, 3))
# 循环绘制每位同学的雷达图
for (i in 1:6) {
radarchart(
data[c(1, 2, i + 2), ], # 选取最大值、最小值和第i位同学的数据
axistype = 1, # 坐标轴类型
# 多边形样式
pcol = colors_border[i], # 多边形边框颜色
pfcol = colors_in[i], # 多边形填充颜色
plwd = 4, # 多边形边框线宽
plty = 1, # 多边形线型
# 网格样式
cglcol = "grey", # 网格线颜色
cglty = 1, # 网格线类型
axislabcol = "grey", # 轴标签颜色
caxislabels = seq(0, 20, 5), # 轴标签内容
cglwd = 0.8, # 网格线宽
# 标签样式
vlcex = 0.8, # 变量标签字体大小
# 子图标题
title = mytitle[i]
)
}
# 恢复默认的画布设置
par(mfrow = c(1, 1))
```
## `ggradar`
首先准备数据:
```{r}
#| fig-cap: "企鹅三种类在各特征上的标准化均值雷达图(ggradar)"
# 加载palmerpenguins数据集
data("penguins", package = "palmerpenguins")
# 数据整理:去除缺失值,按species分组,计算各特征均值,并标准化到[0,1]区间
penguins_radar <- penguins |>
drop_na() |>
group_by(species) |>
summarise(
avg_bill_length = mean(bill_length_mm), # 喙长均值
avg_bill_dept = mean(bill_depth_mm), # 喙深均值
avg_flipper_length = mean(flipper_length_mm), # 翼长均值
avg_body_mass = mean(body_mass_g) # 体重均值
) |>
ungroup() |>
mutate(across(-species, rescale)) # 除species外所有列标准化到[0,1]
```
```{r}
#| fig-cap: "企鹅三种类在各特征上的标准化均值雷达图(ggradar)"
# 使用ggradar包绘制企鹅三种类在各特征上的标准化均值雷达图
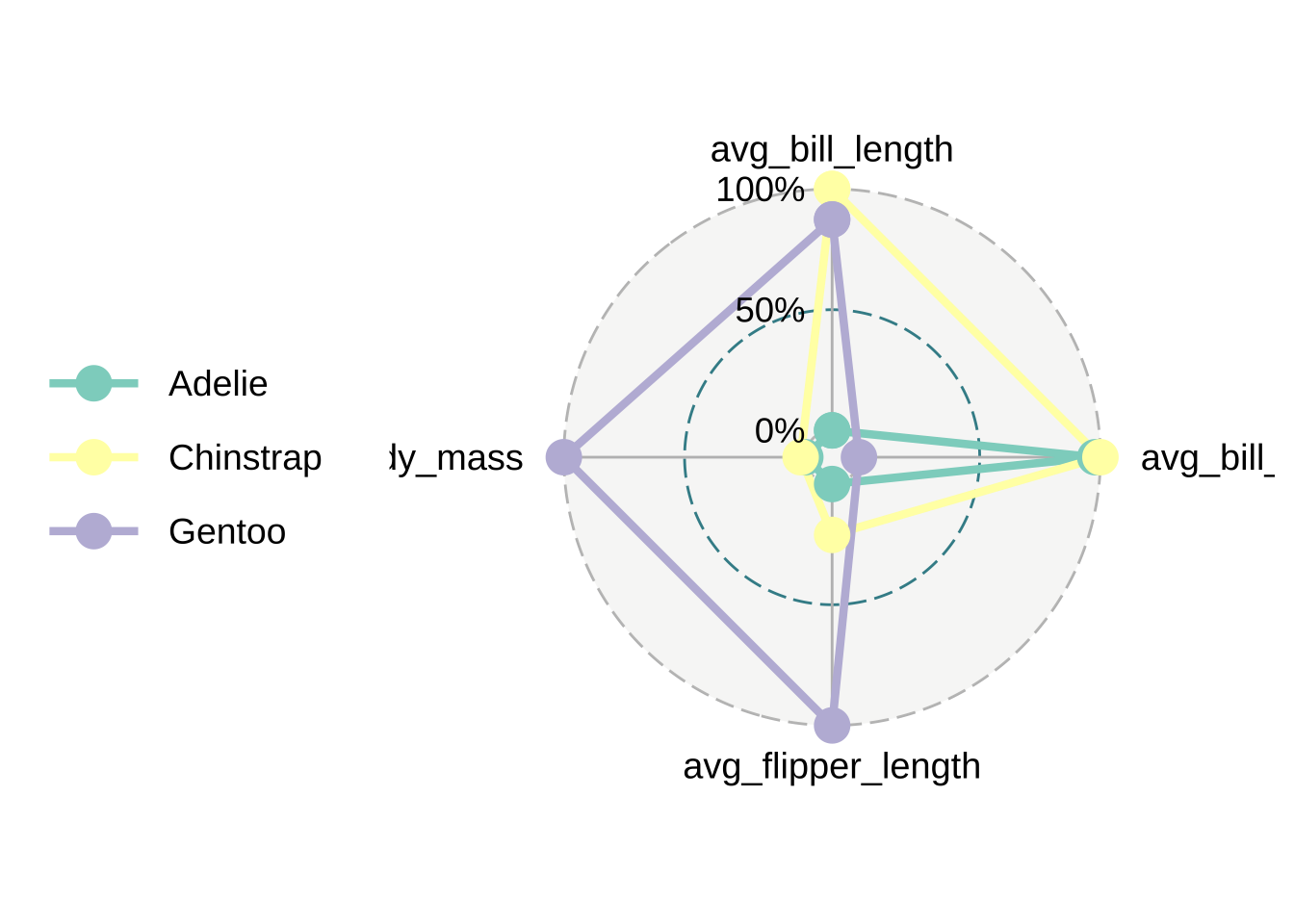
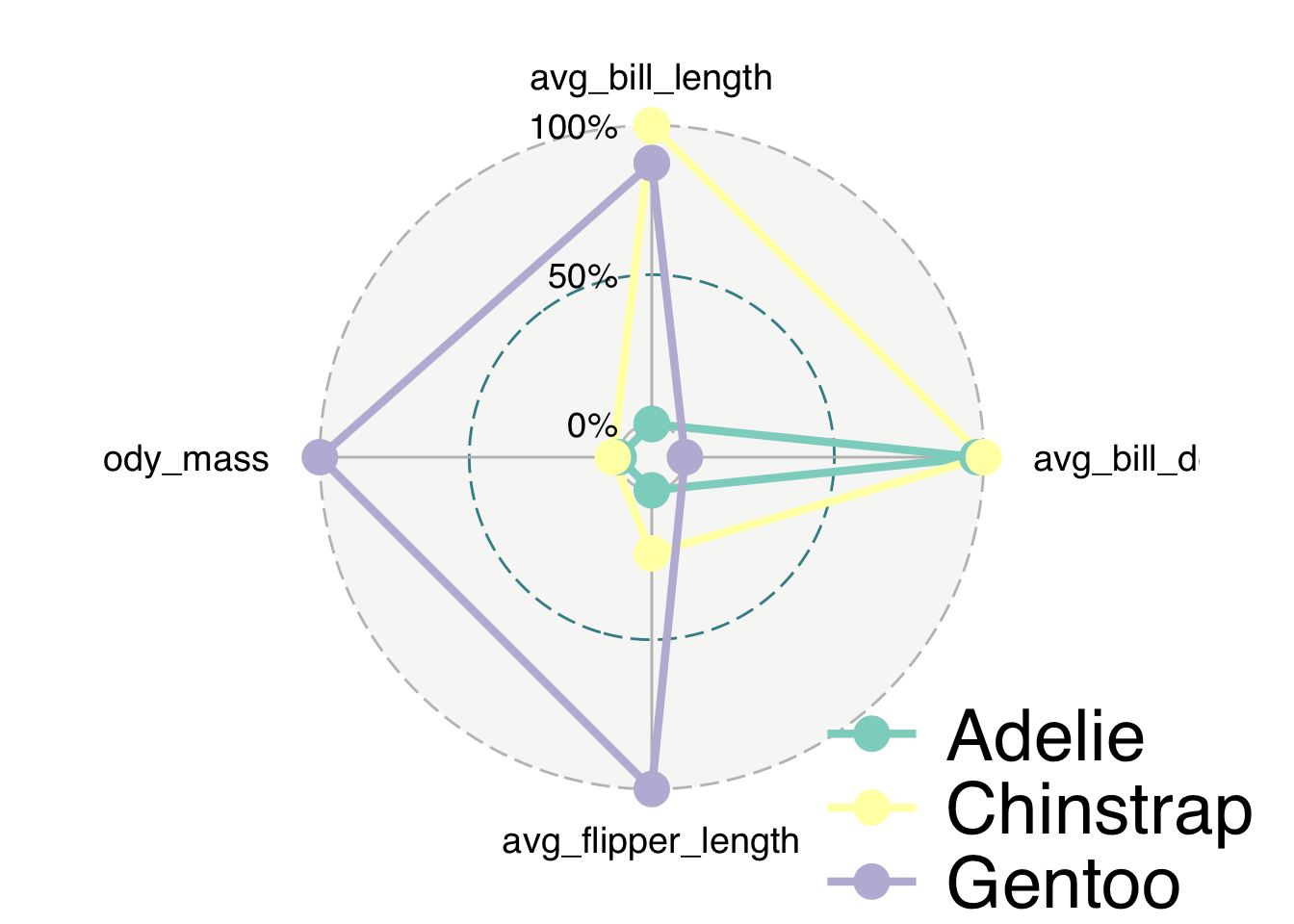
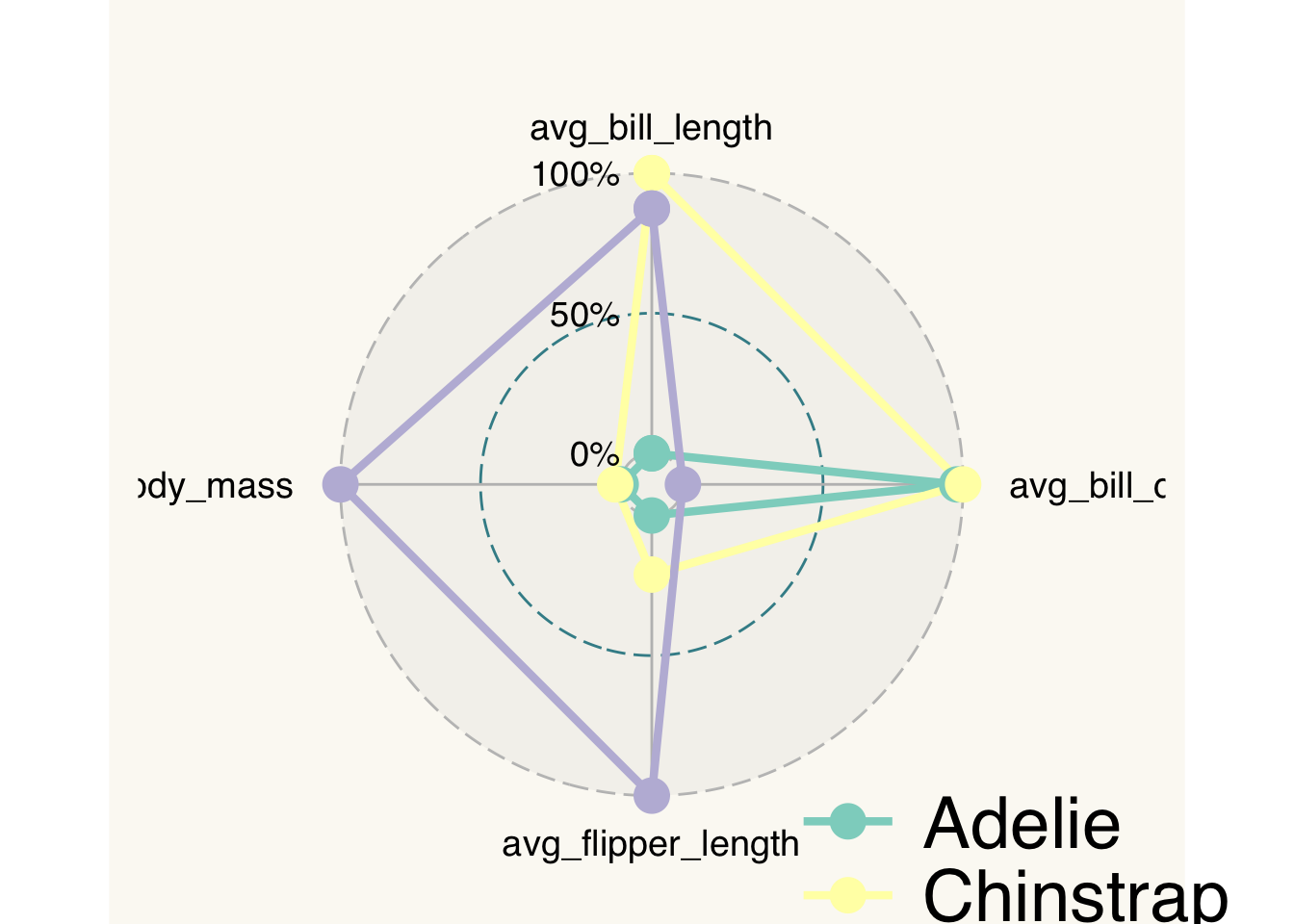
plt <- penguins_radar |> ggradar()
plt
```
```{r}
#| fig-cap: "美化后的企鹅三种类标准化均值雷达图(ggradar)"
# 对ggradar绘图对象进行美化,调整图例位置、字体和背景
plt <- plt +
theme(
legend.position = c(0.85, 0.1), # 图例位置
legend.text = element_text(size = 28), # 图例文字大小
legend.key = element_rect(fill = NA, color = NA), # 图例键背景
legend.background = element_blank() # 图例背景
)
plt
```
```{r}
#| fig-cap: "美化最终版后的企鹅三种类标准化均值雷达图(ggradar)"
plt <- plt +
labs(title = "Radar plot of penguins species") +
theme(
plot.background = element_rect(fill = "#fbf9f4", color = "#fbf9f4"),
panel.background = element_rect(fill = "#fbf9f4", color = "#fbf9f4"),
plot.title.position = "plot", # slightly different from default
plot.title = element_text(
family = "lobstertwo",
size = 62,
face = "bold",
color = "#2a475e"
)
)
plt
```
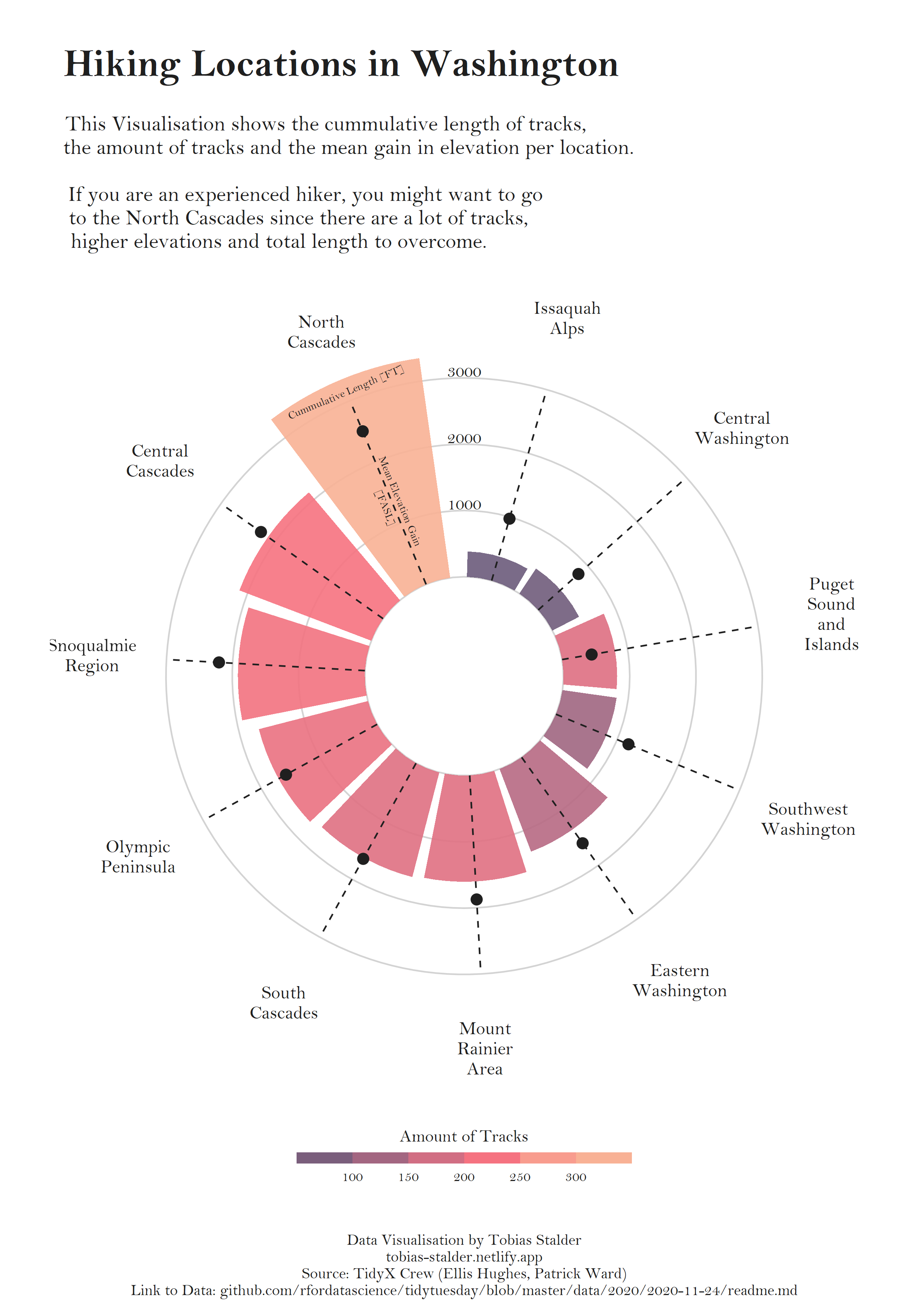
## Pearl
- [Hiking Locations in Washington](https://r-graph-gallery.com/web-circular-barplot-with-R-and-ggplot2.html) 的优美环状条形图