Show/Hide Code
# Libraries
library(tidyverse)
library(hrbrthemes) # 主题
library(patchwork) # 拼接图
library(GGally) # 平行坐标图
library(viridis) # 颜色
library(ggbump) # 平行坐标图# Libraries
library(tidyverse)
library(hrbrthemes) # 主题
library(patchwork) # 拼接图
library(GGally) # 平行坐标图
library(viridis) # 颜色
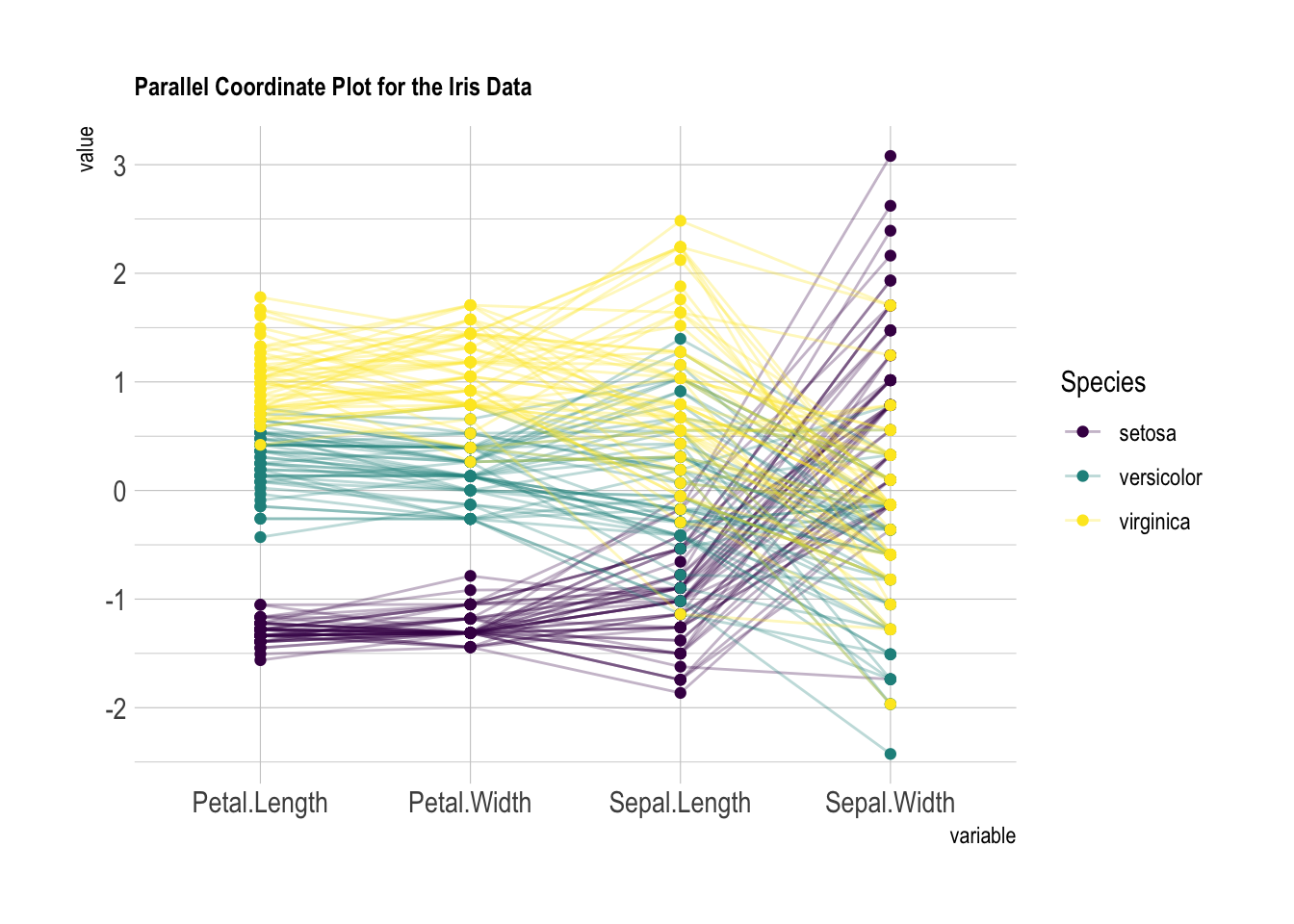
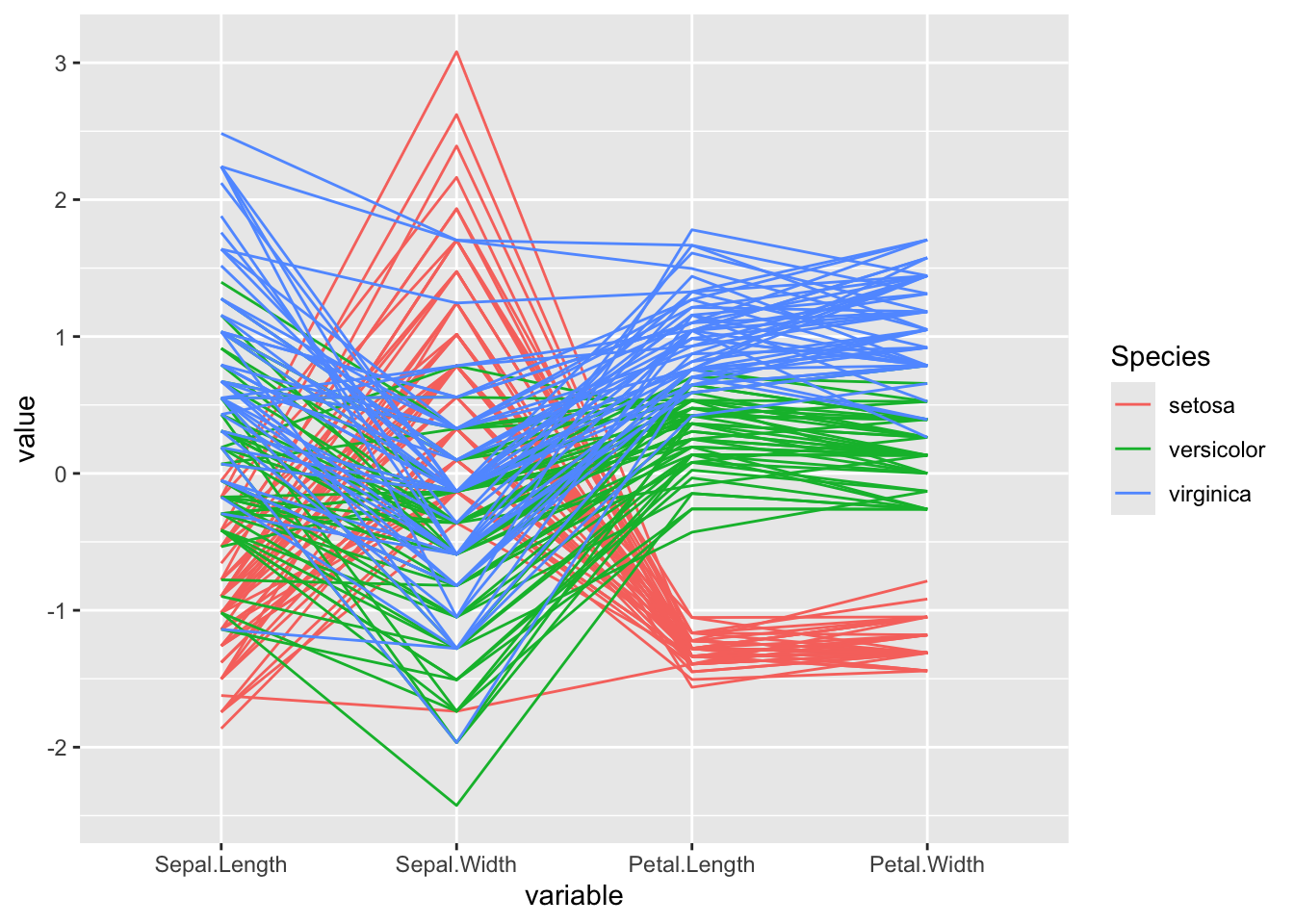
library(ggbump) # 平行坐标图ìris 数据集为 150 朵花样本(每朵用颜色线表示)提供了四个特征(每个用垂直线表示)。样本分为三种物种。下方的图表高效地突显出,山鸢尾的花瓣较小,但其萼片倾向于更宽。
平行坐标图相当于蜘蛛图,但使用笛卡尔坐标。比蜘蛛图更易于阅读,尤其是当变量/观测数量较多时。
# 使用R自带的iris数据集
data <- iris
# 绘制平行坐标图
data |>
ggparcoord(
columns = 1:4, # 选择前4列作为变量
groupColumn = 5, # 第5列(Species)作为分组变量
order = "anyClass", # 自动排序变量
showPoints = TRUE, # 显示数据点
title = "Parallel Coordinate Plot for the Iris Data", # 图标题
alphaLines = 0.3 # 线条透明度
) +
scale_color_viridis(discrete = TRUE) + # 使用viridis色带
theme_ipsum() + # 应用hrbrthemes主题
theme(
plot.title = element_text(size = 10) # 设置标题字体大小
)
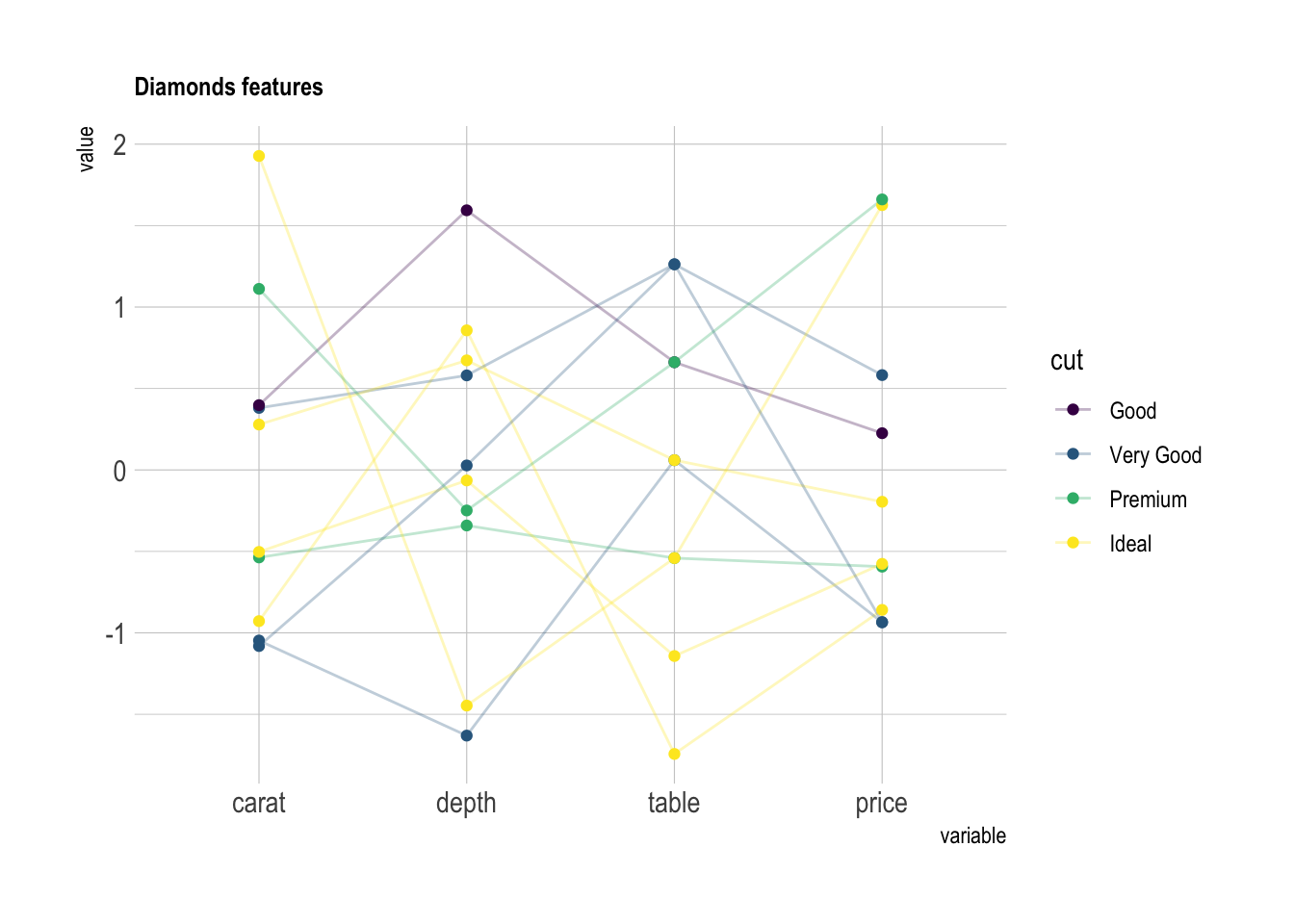
变量 和 单位 可以不同:
下图比较了四个使用不同单位的变量,例如价格(美元)或深度(百分比)。请注意使用缩放 (见下文) 以便进行比较。
# 从diamonds数据集中随机抽取10个样本,绘制平行坐标图
diamonds |>
sample_n(10) |> # 随机抽取10行
ggparcoord(
columns = c(1, 5:7), # 选择第1、5、6、7列作为变量
groupColumn = 2, # 用第2列(cut)作为分组变量
#order = "anyClass", # 可选:自动排序变量
showPoints = TRUE, # 显示数据点
title = "Diamonds features", # 图标题
alphaLines = 0.3 # 线条透明度
) +
scale_color_viridis(discrete = TRUE) + # 使用viridis色带
theme_ipsum() + # 应用hrbrthemes主题
theme(
plot.title = element_text(size = 10) # 设置标题字体大小
)
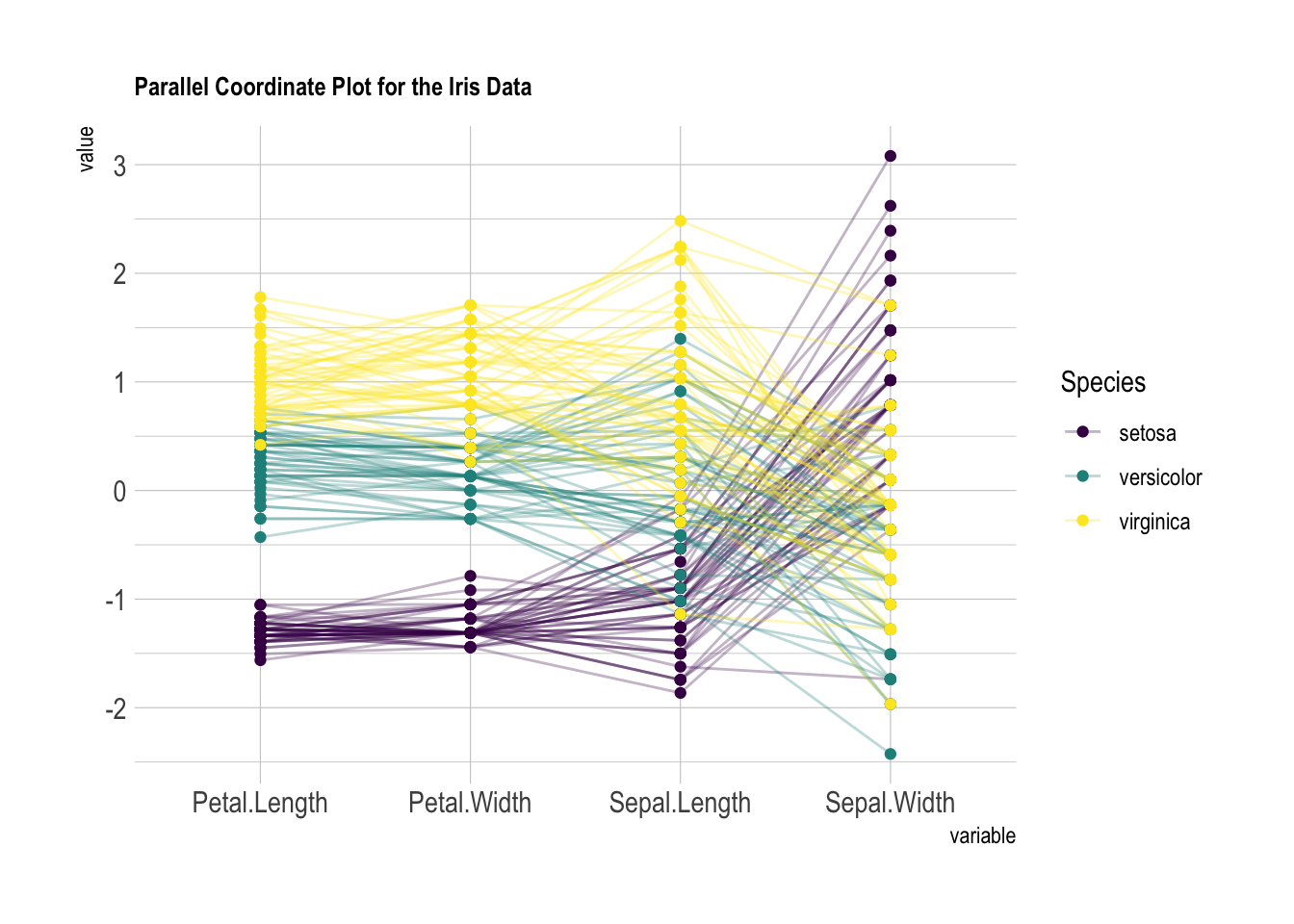
坐标轴顺序:
# 原始顺序的平行坐标图
p1 <- data |>
ggparcoord(
columns = 1:4, # 选择前4列作为变量
groupColumn = 5, # 第5列(Species)作为分组变量
order = c(1:4), # 按原始顺序排列坐标轴
showPoints = TRUE, # 显示数据点
title = "Original", # 图标题
alphaLines = 0.3 # 线条透明度
) +
scale_color_viridis(discrete = TRUE) + # 使用viridis色带
theme_ipsum() + # 应用hrbrthemes主题
theme(
legend.position = "default", # 图例位置为默认
plot.title = element_text(size = 10) # 设置标题字体大小
) +
xlab("")
# 自动排序后的平行坐标图
p2 <- data |>
ggparcoord(
columns = 1:4, # 选择前4列作为变量
groupColumn = 5, # 第5列(Species)作为分组变量
order = "anyClass", # 自动排序坐标轴
showPoints = TRUE, # 显示数据点
title = "Re-ordered", # 图标题
alphaLines = 0.3 # 线条透明度
) +
scale_color_viridis(discrete = TRUE) +
theme_ipsum() +
theme(
legend.position = "none", # 不显示图例
plot.title = element_text(size = 10)
) +
xlab("")
# 拼接两个不同坐标轴顺序的平行坐标图
p1 + p2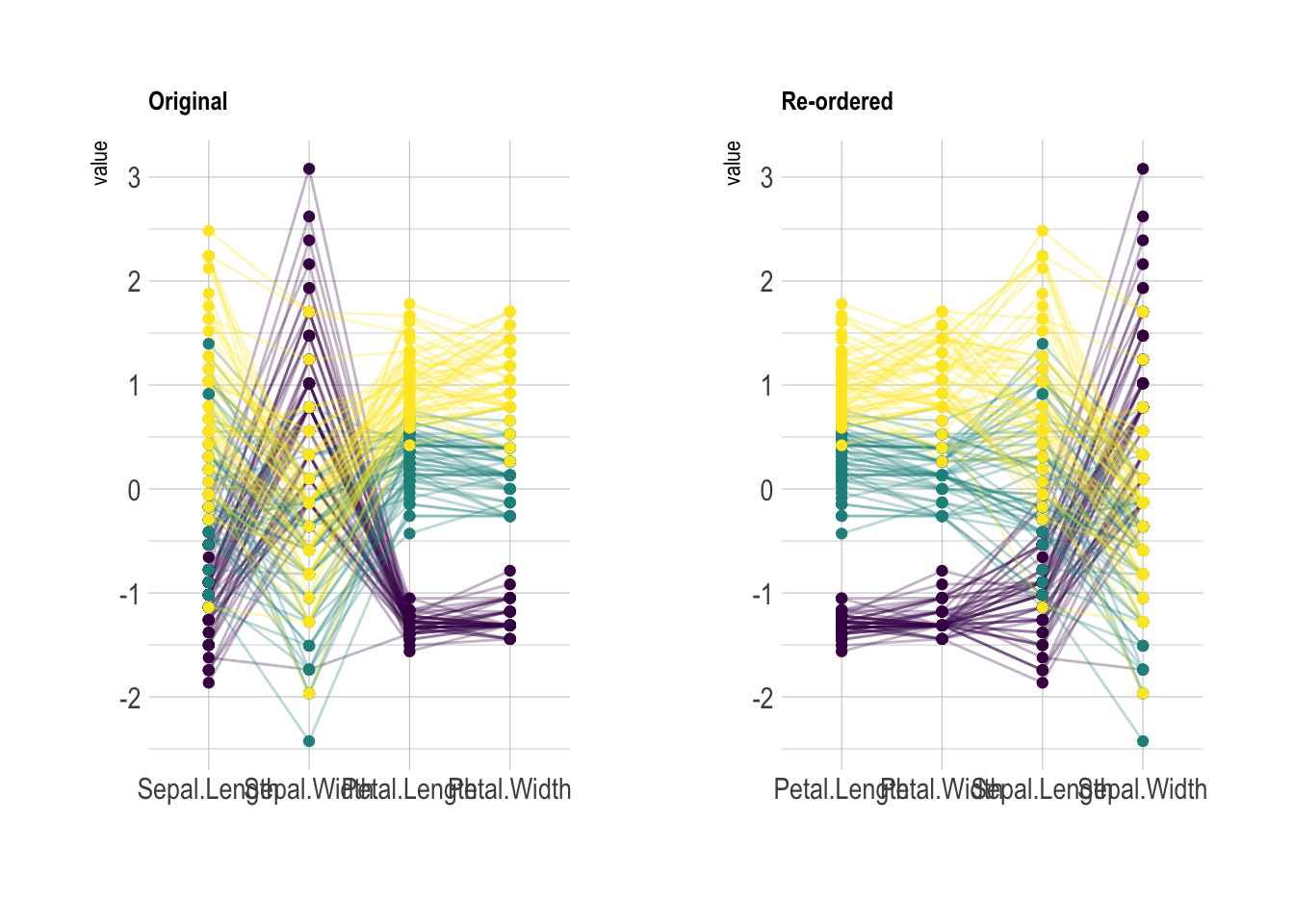
关键点:
ggally# 使用ggparcoord函数绘制iris数据集的基础平行坐标图
iris |>
ggparcoord(
columns = 1:4, # 选择前4列作为变量(花萼长度、花萼宽度、花瓣长度、花瓣宽度)
groupColumn = 5 # 第5列(Species)作为分组变量,不同物种用不同颜色区分
)
# 使用ggparcoord绘制iris数据集的平行坐标图,并进行详细定制
iris |>
ggparcoord(
columns = 1:4, # 选择前4列作为变量(花萼长度、花萼宽度、花瓣长度、花瓣宽度)
groupColumn = 5, # 第5列(Species)作为分组变量,不同物种用不同颜色区分
order = "anyClass", # 自动排序变量顺序,减少线条交叉
showPoints = TRUE, # 显示每个观测点
title = "Parallel Coordinate Plot for the Iris Data", # 图标题
alphaLines = 0.3 # 线条透明度,便于观察重叠
) +
scale_color_viridis(discrete = TRUE) + # 使用viridis色带,提升可读性
theme_ipsum() + # 应用hrbrthemes主题,美化图形
theme(
plot.title = element_text(size = 10) # 设置标题字体大小
)
ggally 的 scale 参数有四种可能的选项:
# 不进行缩放
p1 <- data |>
ggparcoord(
columns = 1:4, # 选择前4列作为变量
groupColumn = 5, # 第5列(Species)作为分组变量
order = "anyClass", # 自动排序变量
scale = "globalminmax", # 全局最小最大值缩放(无缩放)
showPoints = TRUE, # 显示数据点
title = "No scaling", # 图标题
alphaLines = 0.3 # 线条透明度
) +
scale_color_viridis(discrete = TRUE) + # 使用viridis色带
theme_ipsum() + # 应用hrbrthemes主题
theme(
legend.position = "none", # 不显示图例
plot.title = element_text(size = 10) # 设置标题字体大小
) +
xlab("")
# 每个变量标准化到[0,1]区间
p2 <- data |>
ggparcoord(
columns = 1:4, # 选择前4列作为变量
groupColumn = 5, # 第5列(Species)作为分组变量
order = "anyClass", # 自动排序变量
scale = "uniminmax", # 每个变量单独缩放到[0,1]
showPoints = TRUE, # 显示数据点
title = "Standardize to Min = 0 and Max = 1", # 图标题
alphaLines = 0.3 # 线条透明度
) +
scale_color_viridis(discrete = TRUE) +
theme_ipsum() +
theme(
legend.position = "none",
plot.title = element_text(size = 10)
) +
xlab("")
# 每个变量减去均值再除以标准差(标准化)
p3 <- data |>
ggparcoord(
columns = 1:4, # 选择前4列作为变量
groupColumn = 5, # 第5列(Species)作为分组变量
order = "anyClass", # 自动排序变量
scale = "std", # 标准化(减均值除标准差)
showPoints = TRUE, # 显示数据点
title = "Normalize univariately (substract mean & divide by sd)", # 图标题
alphaLines = 0.3 # 线条透明度
) +
scale_color_viridis(discrete = TRUE) +
theme_ipsum() +
theme(
legend.position = "none",
plot.title = element_text(size = 10)
) +
xlab("")
# 每个变量中心化(减去均值)
p4 <- data |>
ggparcoord(
columns = 1:4, # 选择前4列作为变量
groupColumn = 5, # 第5列(Species)作为分组变量
order = "anyClass", # 自动排序变量
scale = "center", # 中心化(减去均值)
showPoints = TRUE, # 显示数据点
title = "Standardize and center variables", # 图标题
alphaLines = 0.3 # 线条透明度
) +
scale_color_viridis(discrete = TRUE) +
theme_ipsum() +
theme(
legend.position = "none",
plot.title = element_text(size = 10)
) +
xlab("")
# 拼接四种缩放方式的平行坐标图
p1 + p2 + p3 + p4 + plot_layout(ncol = 2)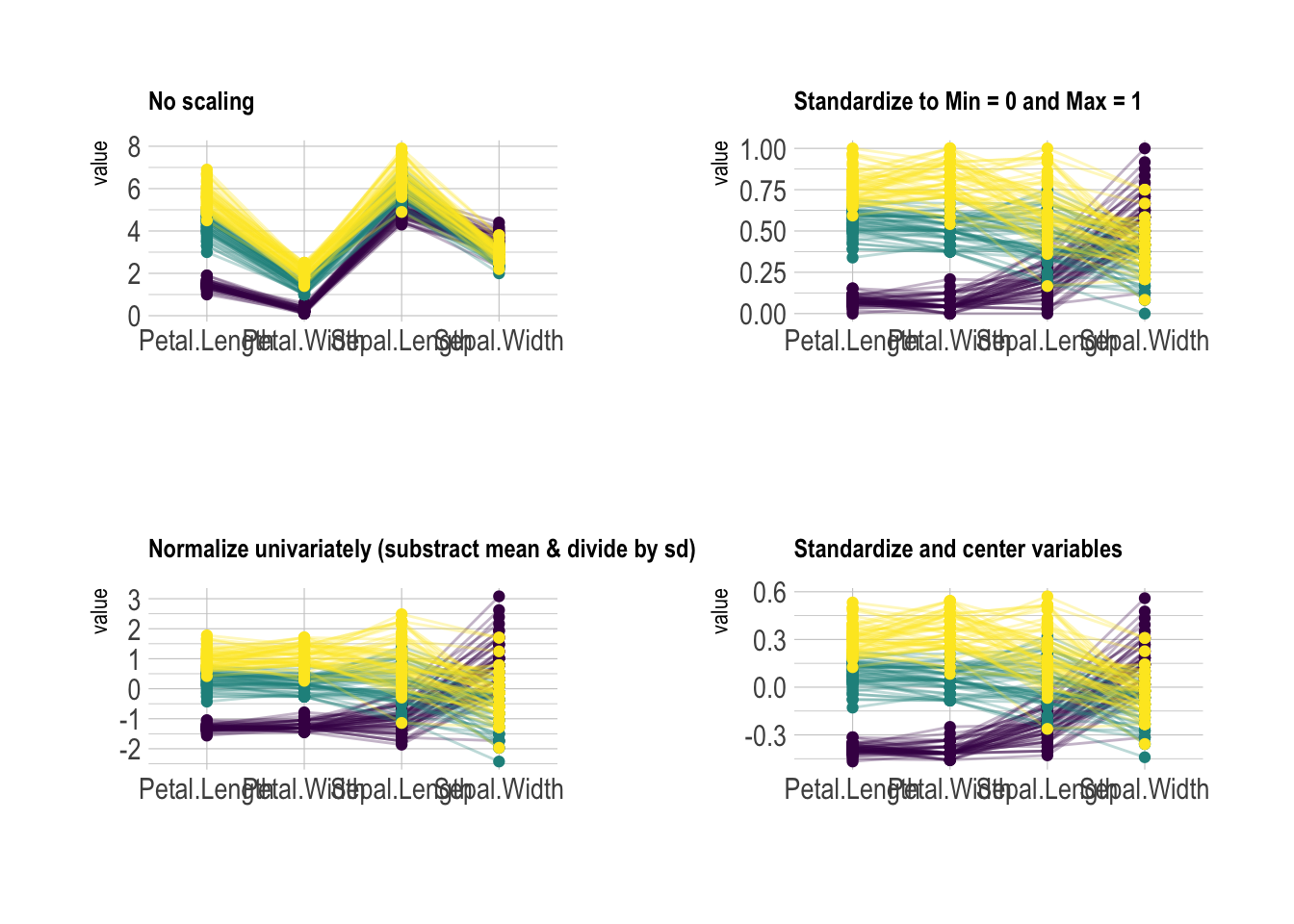
data |>
ggparcoord(
columns = 1:4, # 选择前4列作为变量
groupColumn = 5, # 第5列(Species)作为分组变量
order = "anyClass", # 自动排序变量顺序
showPoints = TRUE, # 显示数据点
title = "Original", # 图标题
alphaLines = 0.3 # 线条透明度
) +
scale_color_manual(values = c("#69b3a2", "grey", "grey")) + # 手动设置颜色,突出显示第一个类别
theme_ipsum() + # 应用hrbrthemes主题
theme(
legend.position = "default", # 图例位置为默认
plot.title = element_text(size = 10) # 设置标题字体大小
) +
xlab("") # 去除x轴标签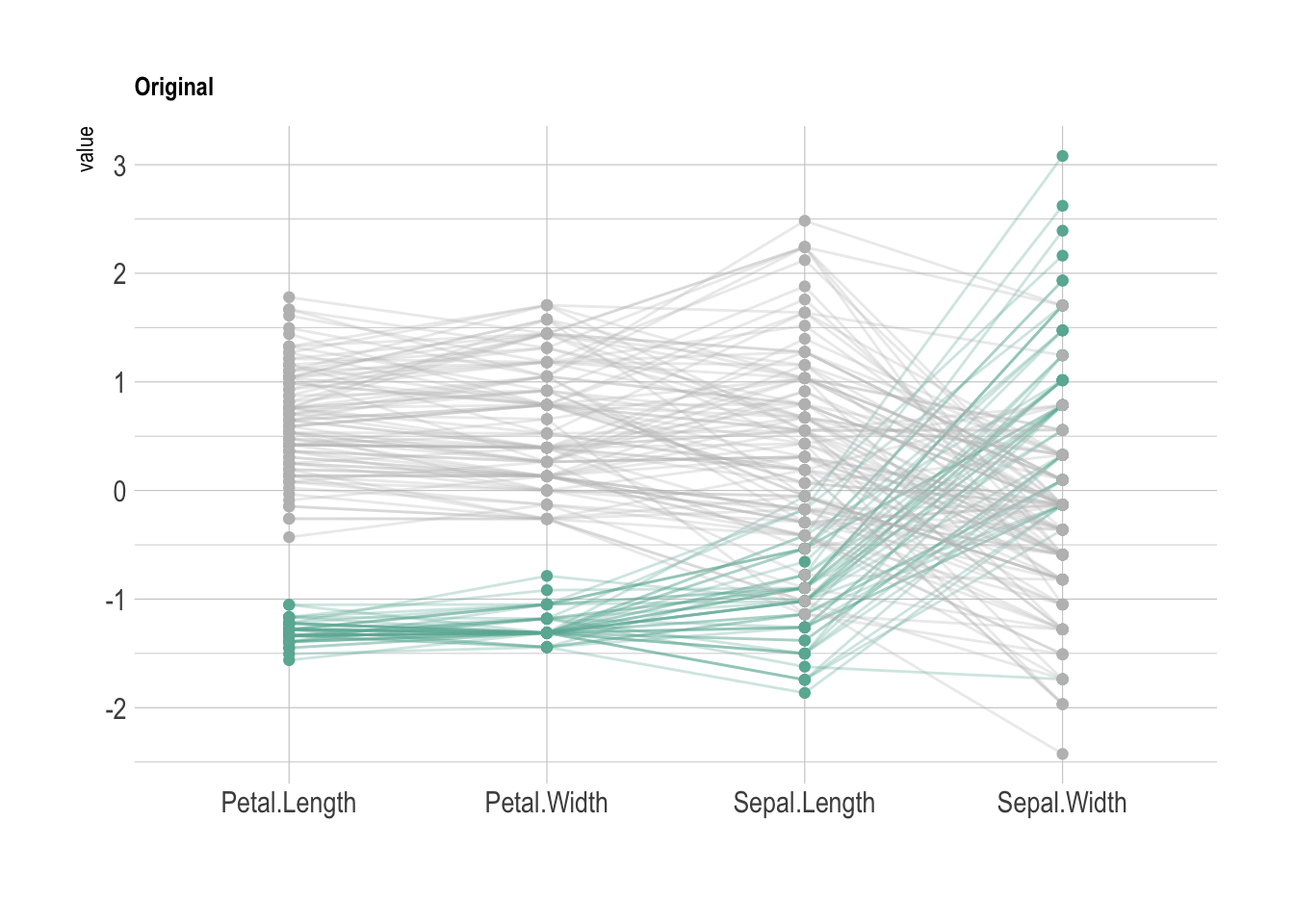
mass顺序至关重要呢! 需要改变输入数据的列顺序,以便在平行坐标图中正确显示变量。
# 加载所需包
library(MASS) # 提供parcoord函数
library(RColorBrewer) # 提供调色板
# 设置调色板,选用Set1配色方案的前3种颜色
palette <- brewer.pal(3, "Set1")
# 根据iris数据集的Species列为每个样本分配颜色
my_colors <- palette[as.numeric(iris$Species)]
# 使用parcoord函数绘制平行坐标图
parcoord(
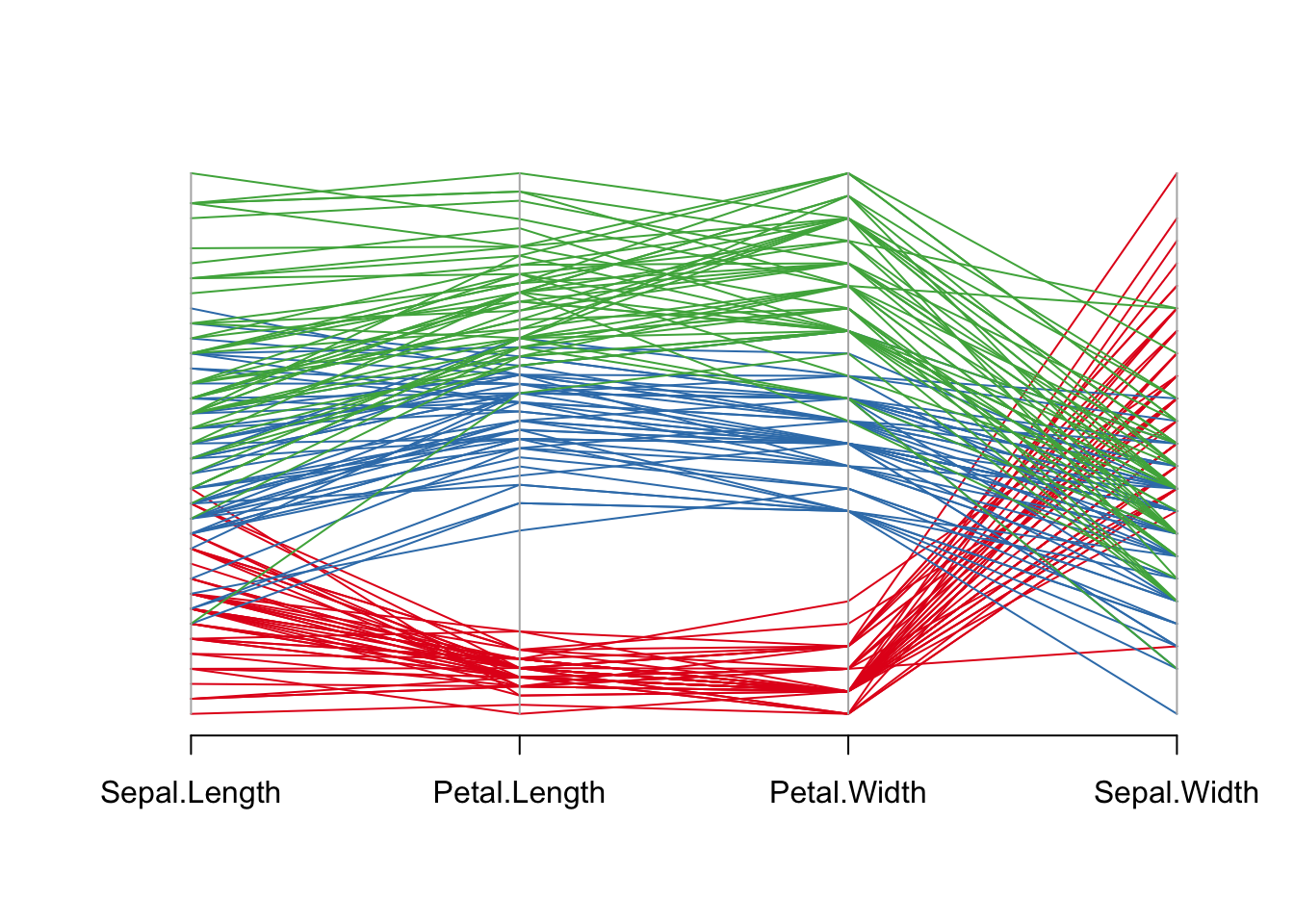
iris[, c(1, 3, 4, 2)], # 选择变量顺序(花萼长度、花瓣长度、花瓣宽度、花萼宽度)
col = my_colors # 按物种分配颜色
)
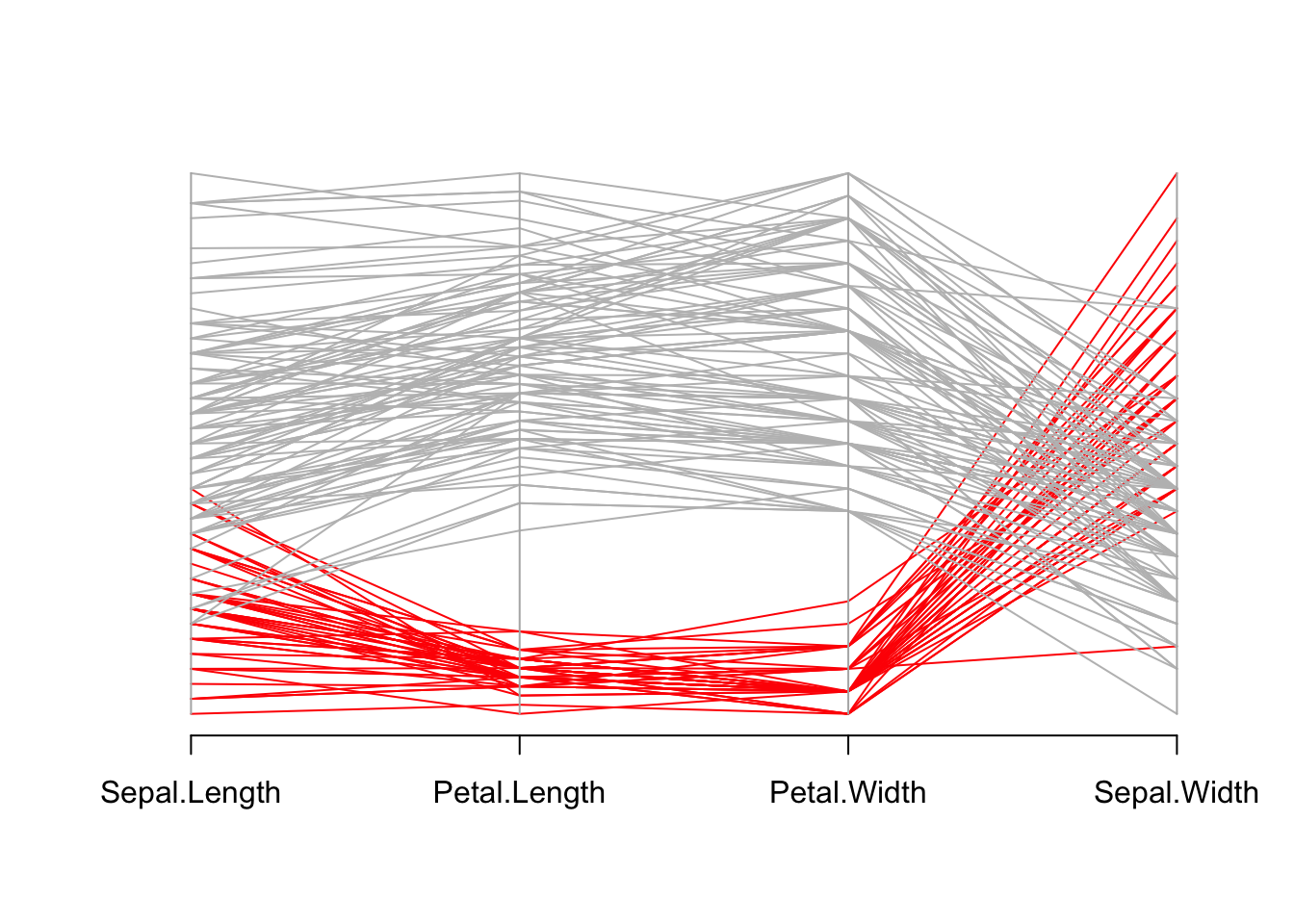
# 创建一个颜色向量,setosa类别为红色,其余为灰色
isSetosa <- ifelse(iris$Species == "setosa", "red", "grey")
# 使用parcoord函数绘制平行坐标图
# 选择变量顺序(花萼长度、花瓣长度、花瓣宽度、花萼宽度)
# setosa类别用红色高亮,其余类别为灰色
parcoord(
iris[, c(1, 3, 4, 2)], # 选择变量顺序
col = isSetosa # 按类别分配颜色
)
ggbump# 创建数据
year <- rep(2019:2021, 3) # 年份,每个门店3年
products_sold <- c(
500, 600, 700, # Store A 各年份销量
550, 650, 600, # Store B 各年份销量
600, 400, 500 # Store C 各年份销量
)
store <- c(
"Store A", "Store A", "Store A",
"Store B", "Store B", "Store B",
"Store C", "Store C", "Store C"
)
# 创建数据框
df <- data.frame(
year = year,
products_sold = products_sold,
store = store
)
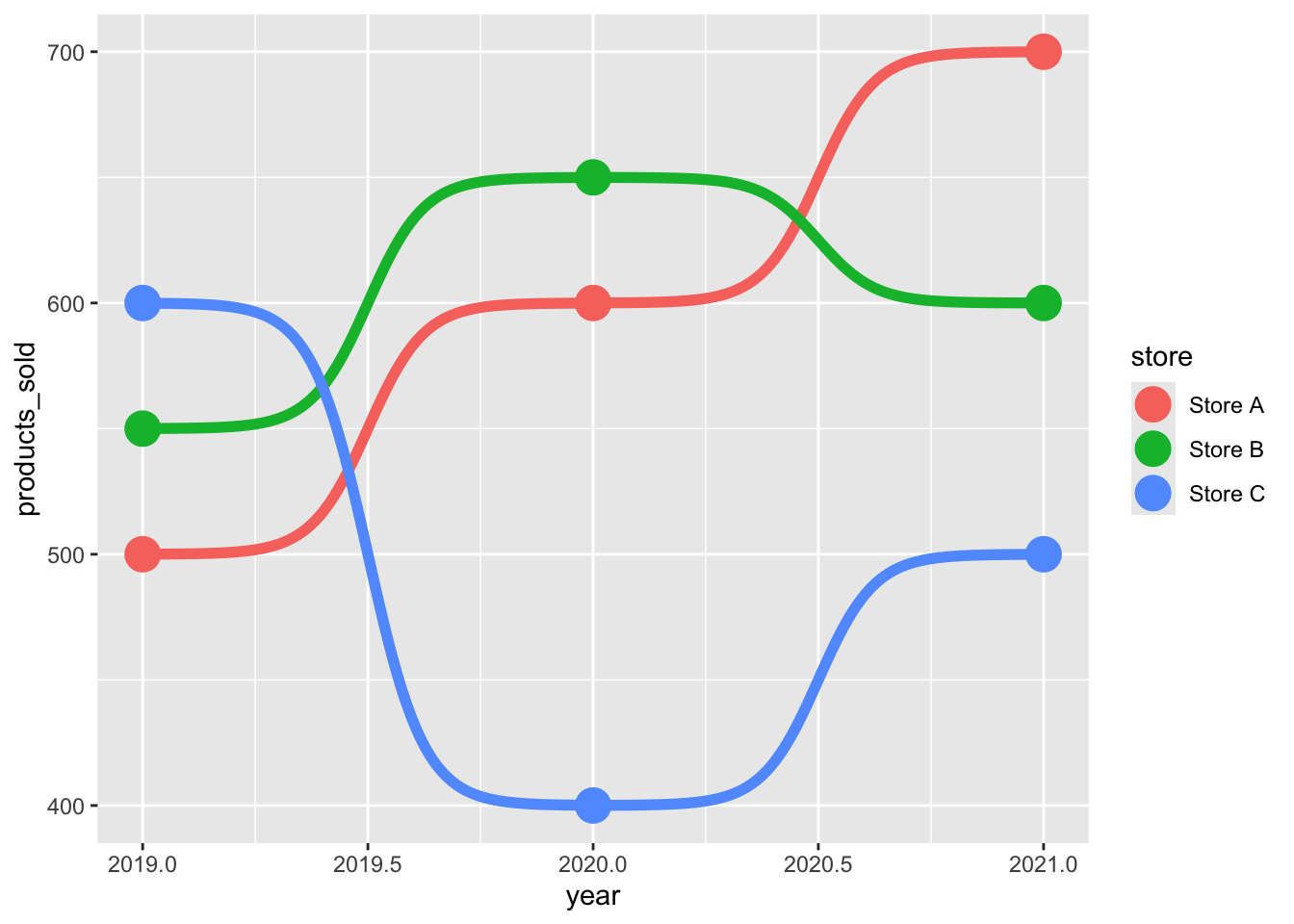
# 绘制bump图,展示不同门店产品销量随年份的变化
ggplot(df, aes(x = year, y = products_sold, color = store)) +
geom_bump(size = 2) # 使用geom_bump绘制平滑的连线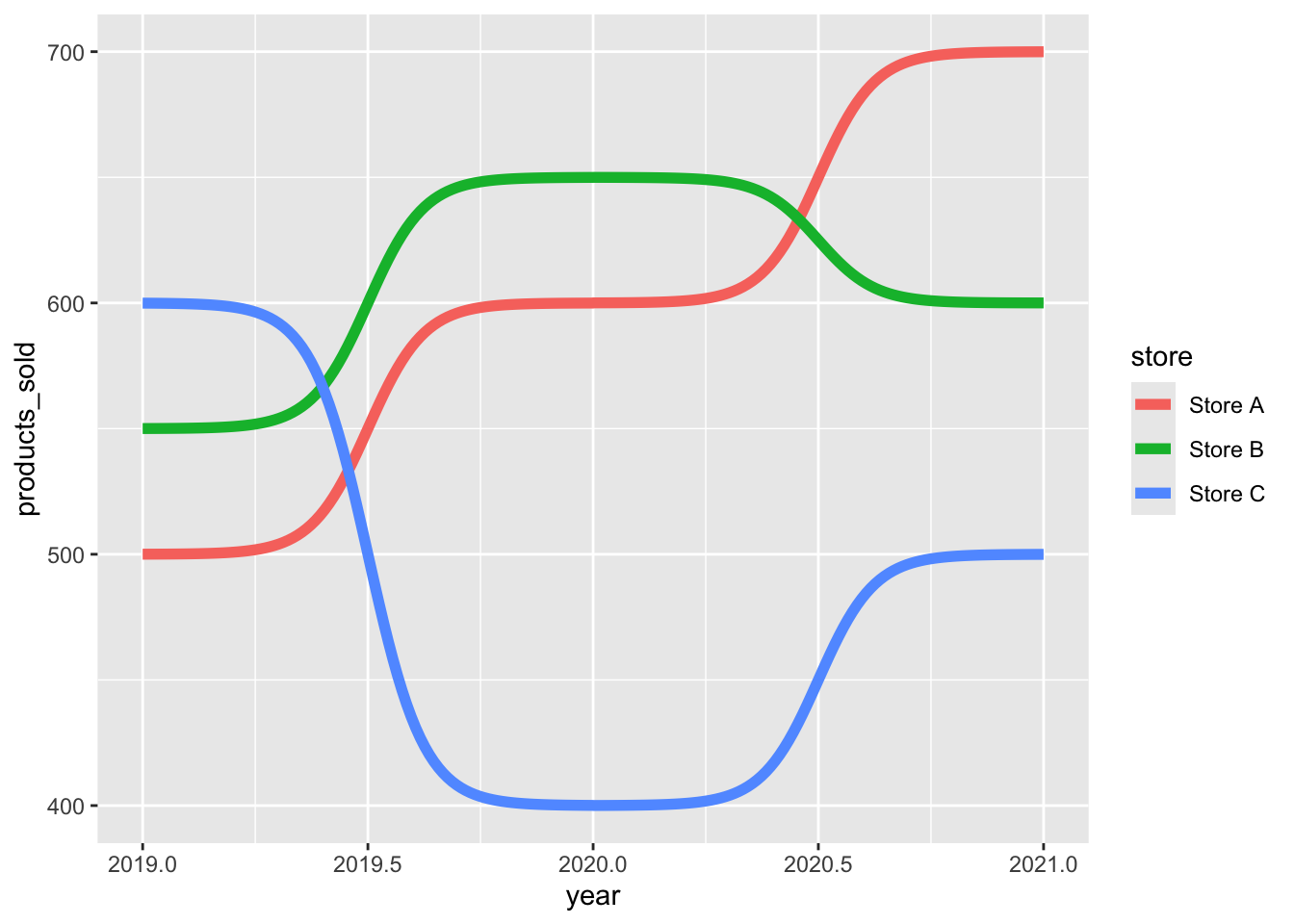
# 使用ggplot绘制bump图,并在每个数据点处添加圆点
ggplot(df, aes(x = year, y = products_sold, color = store)) +
geom_bump(size = 2) + # 绘制平滑的bump连线,展示销量变化趋势
geom_point(size = 6) # 在每个年份的销量位置添加大圆点,突出显示具体数值