Show/Hide Code
library(tidyverse) # tidyverse 包用于数据处理和可视化
library(babynames) # babynames 数据集
library(viridis) # viridis 包用于配色
library(hrbrthemes) # hrbrthemes 包用于美化主题
library(plotly) # plotly 包用于交互式图形line、Area、Stacked Area 的介绍及改进,见:Section 27.2
library(tidyverse) # tidyverse 包用于数据处理和可视化
library(babynames) # babynames 数据集
library(viridis) # viridis 包用于配色
library(hrbrthemes) # hrbrthemes 包用于美化主题
library(plotly) # plotly 包用于交互式图形美国 1880 年至 2015 年间婴儿名字的使用演变情况,六个名字被堆叠在一起表示:
library(tidyverse) # tidyverse 包用于数据处理和可视化
library(babynames) # babynames 数据集
library(viridis) # viridis 包用于配色
library(hrbrthemes) # hrbrthemes 包用于美化主题
library(plotly) # plotly 包用于交互式图形
# 从 babynames 数据集中筛选指定的女性名字,并只保留女性数据
data <- babynames |>
filter(name %in% c("Amanda", "Jessica", "Patricia", "Deborah", "Dorothy", "Helen")) |>
filter(sex == "F")
# 使用 ggplot2 绘制堆叠面积图
data |>
ggplot(aes(x = year, y = n, fill = name)) + # year 为 x 轴,n 为 y 轴,按 name 填充
geom_area() + # 绘制面积图
scale_fill_viridis(discrete = TRUE) + # 使用 viridis 离散色板
theme(legend.position = "none") + # 不显示图例
ggtitle("Popularity of American names in the previous 30 years") + # 添加标题
theme_ipsum() + # 应用 hrbrthemes 主题
theme(legend.position = "none") # 再次确保图例不显示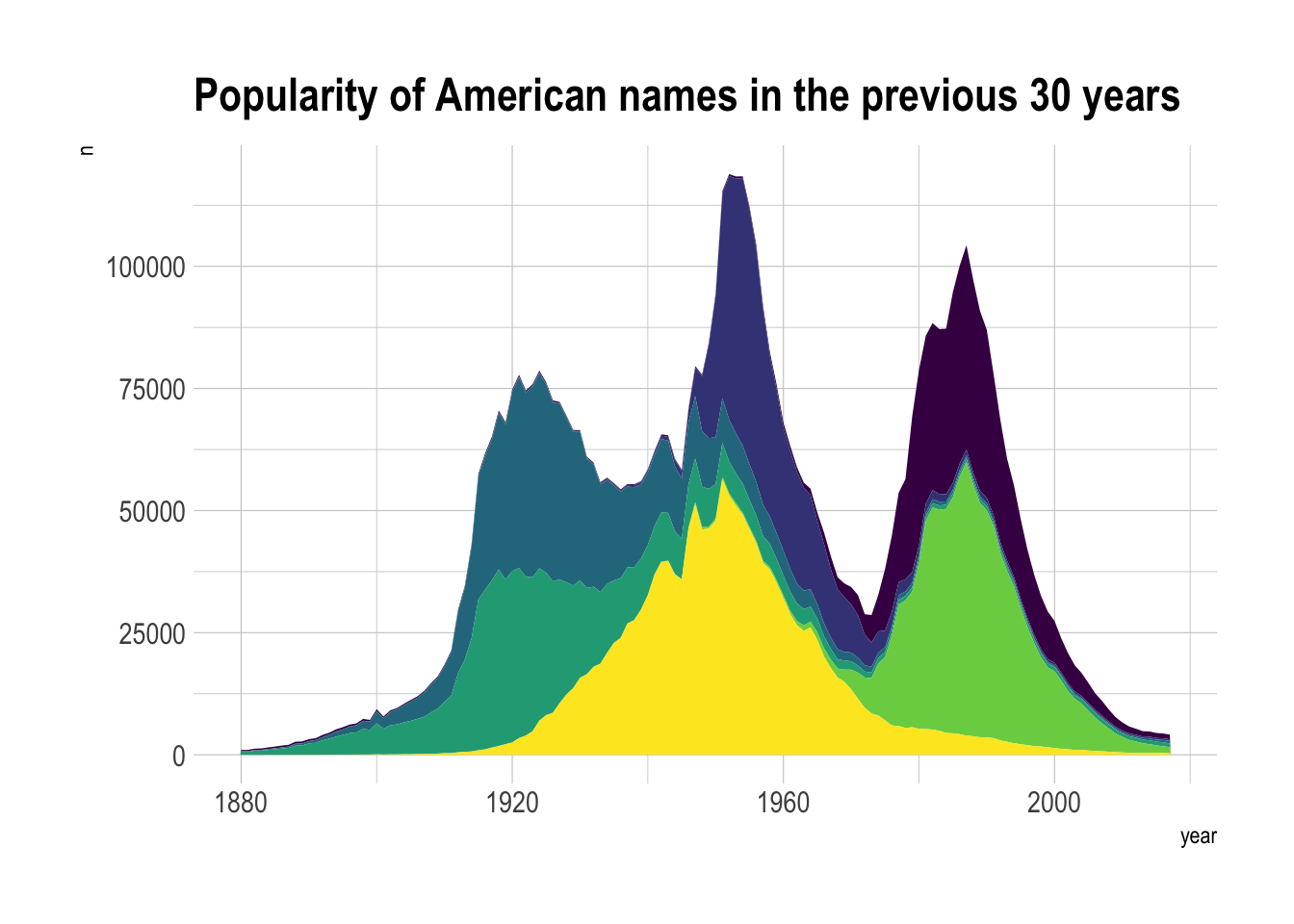
Stacking 在数据可视化中是一种常见做法。它主要出现在三种高度相关的图形类型中:面积图、柱状图和流线图。
缺点是不太观察研究每个组的情况。
有个很严重的问题:视觉错觉:
don <- data.frame(
x = rep(seq(2000, 2005), 3), # x 轴为 2000 到 2005,每组 6 个点,共 3 组
value = c(75, 73, 68, 57, 36, 0, 15, 16, 17, 18, 19, 20, 10, 11, 15, 25, 45, 80), # 每组的数值
group = rep(c("A", "B", "C"), each = 6) # 分组变量,A、B、C 各 6 个
)
# 绘制堆叠面积图,演示视觉错觉
don |>
ggplot(aes(x = x, y = value, fill = group)) + # x 轴为年份,y 轴为数值,按 group 填充颜色
geom_area() + # 绘制面积图
scale_fill_viridis(discrete = TRUE) + # 使用 viridis 离散色板
theme(legend.position = "none") + # 不显示图例
theme_ipsum() + # 应用 hrbrthemes 主题
theme(legend.position = "none") # 再次确保图例不显示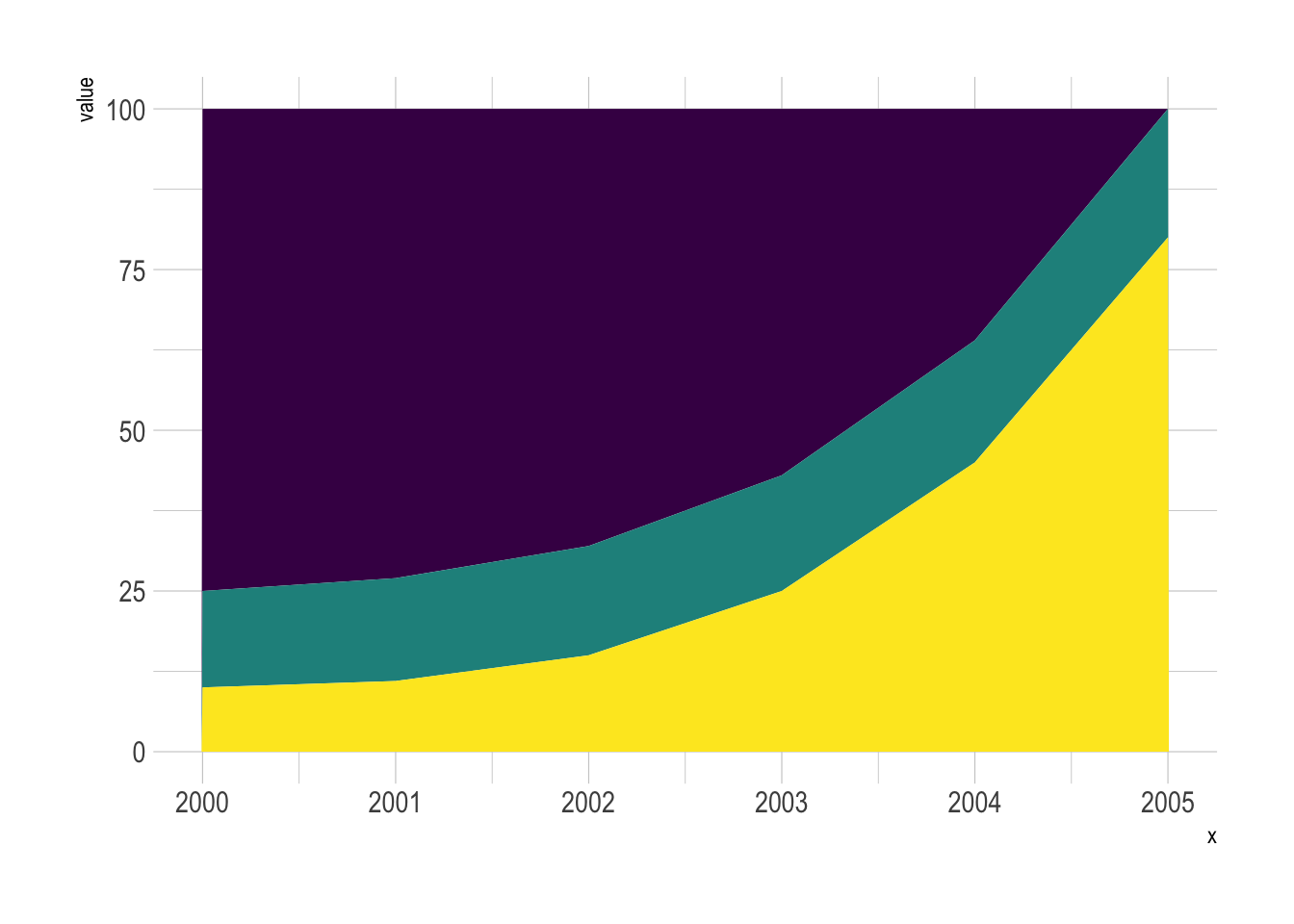
看起来很明显黄色类别增加了,紫色减少了,而绿色……更难阅读。第一眼看上去似乎略微减少了
don |>
filter(group == "B") |>
ggplot(aes(x = x, y = value, fill = group)) + # x 轴为年份,y 轴为数值,按 group 填充颜色
geom_area(fill = "#22908C") + # 绘制面积图,指定填充色
theme(legend.position = "none") + # 不显示图例
theme_ipsum() + # 应用 hrbrthemes 主题
theme(legend.position = "none") # 再次确保图例不显示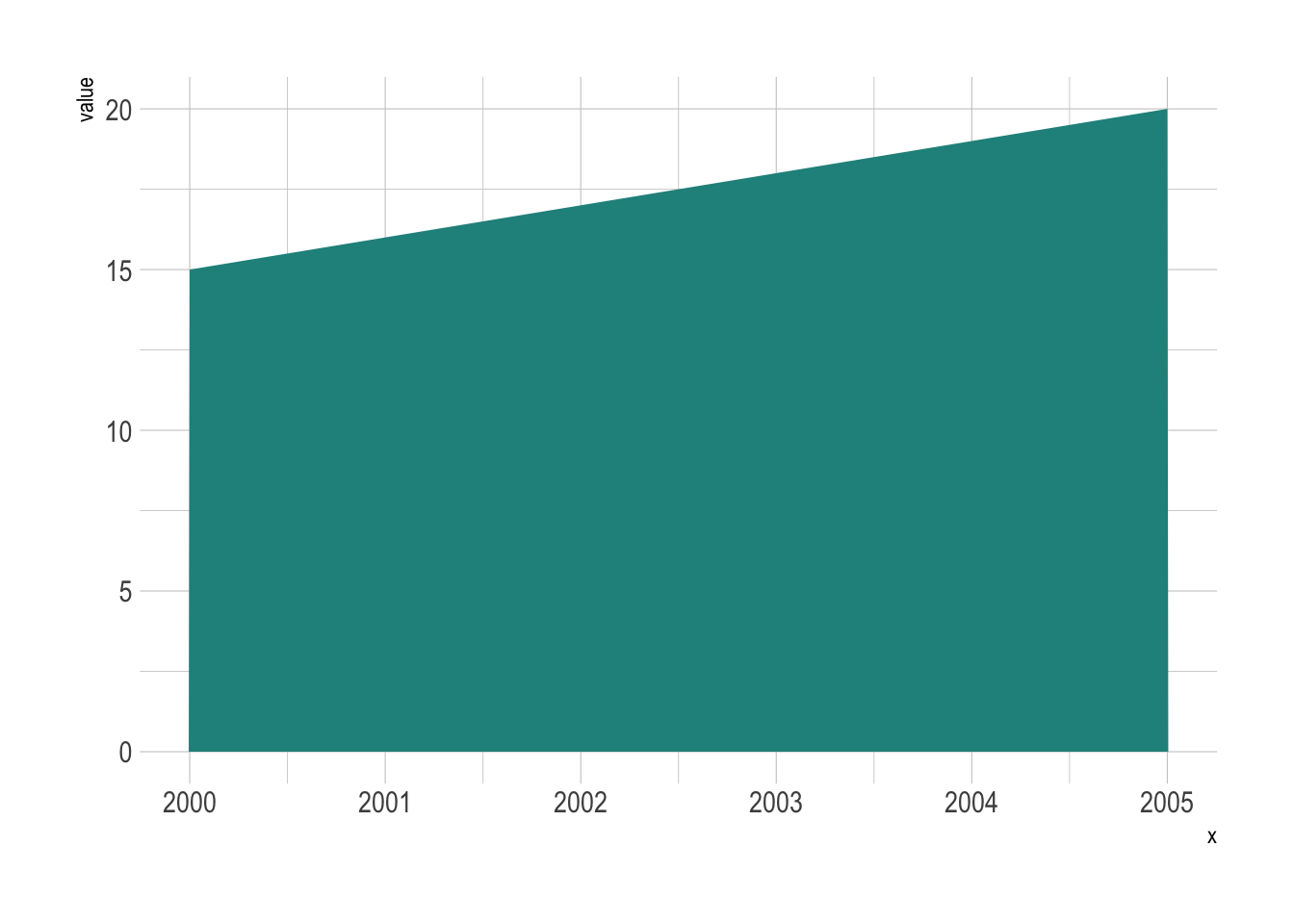
哈哈哈!不仅没有减少,还增多了,视觉错觉!
不如换成折线图:
# 使用新管道 |> 语法,绘制美国女性常见名字的流行趋势折线图
data |>
ggplot(aes(x = year, y = n, group = name, color = name)) + # year 为 x 轴,n 为 y 轴,按 name 分组并着色
geom_line() + # 绘制折线图
scale_color_viridis(discrete = TRUE) + # 使用 viridis 离散色板
theme(legend.position = "none") + # 不显示图例
ggtitle("Popularity of American names in the previous 30 years") + # 添加标题
theme_ipsum() # 应用 hrbrthemes 主题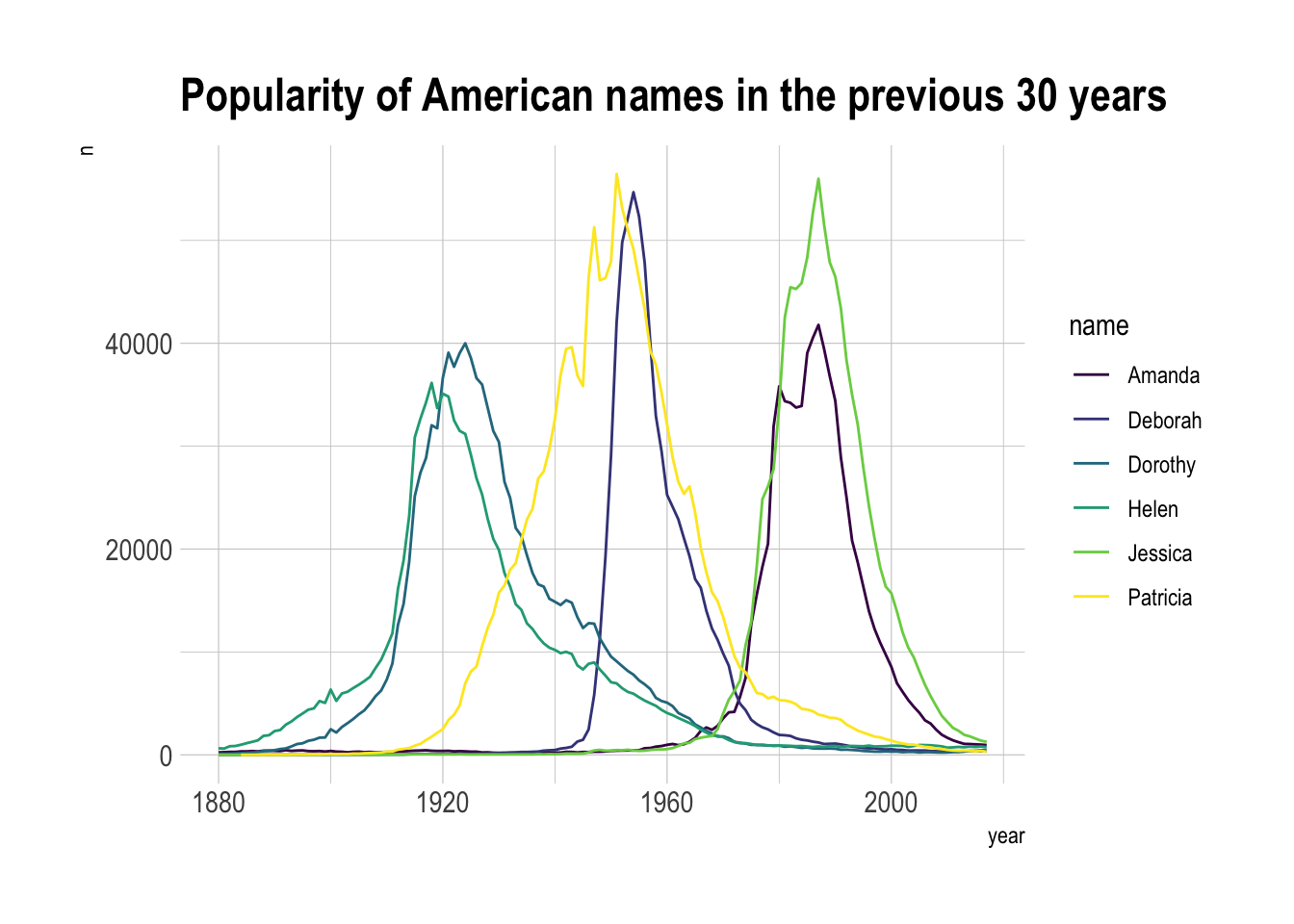
或者分面:
# 绘制每个名字的面积图,并通过 facet_wrap 分面显示
data |>
ggplot(aes(x = year, y = n, group = name, fill = name)) + # year 为 x 轴,n 为 y 轴,按 name 分组和填充
geom_area() + # 绘制面积图
scale_fill_viridis(discrete = TRUE) + # 使用 viridis 离散色板
theme(legend.position = "none") + # 不显示图例
ggtitle("Popularity of American names in the previous 30 years") + # 添加标题
theme_ipsum() + # 应用 hrbrthemes 主题
theme(
legend.position = "none", # 再次确保图例不显示
panel.spacing = unit(0.1, "lines"), # 设置分面之间的间距
strip.text.x = element_text(size = 8) # 设置分面标题字体大小
) +
facet_wrap(~name, scale = "free_y") # 按名字分面,y 轴自适应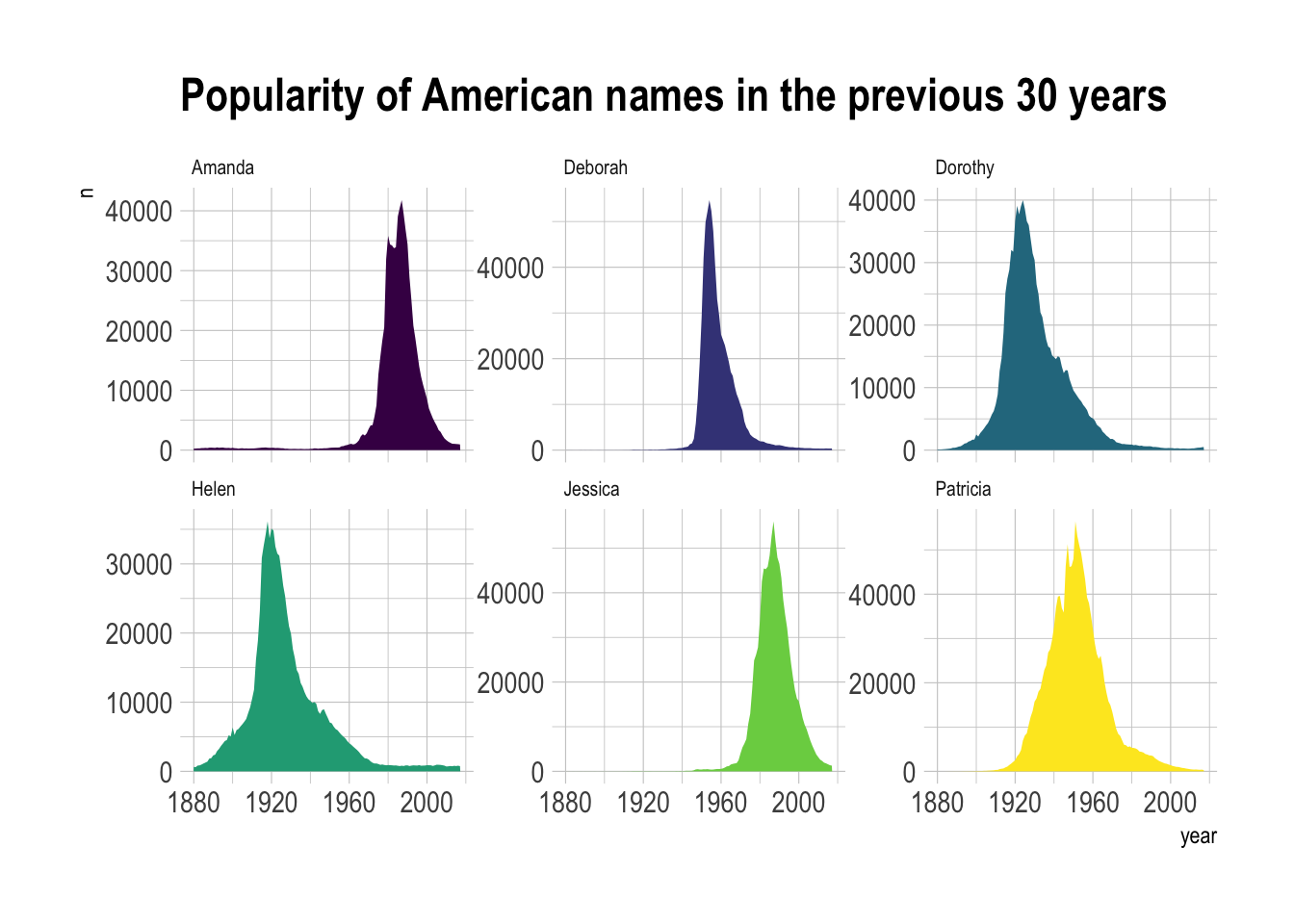
ggplot2library(ggplot2) # ggplot2 包用于数据可视化
library(dplyr) # dplyr 包用于数据处理
# 创建数据
time <- as.numeric(rep(seq(1, 7), each = 7)) # x 轴变量,1 到 7,每个重复 7 次
value <- runif(49, 10, 100) # y 轴变量,49 个 10 到 100 之间的随机数
group <- rep(LETTERS[1:7], times = 7) # 分组变量,A 到 G,每组 7 个
data <- data.frame(time, value, group) # 合并为数据框
# 绘制堆叠面积图
ggplot(data, aes(x = time, y = value, fill = group)) + # 指定数据和映射关系,fill 按 group 分组
geom_area() # 绘制堆叠面积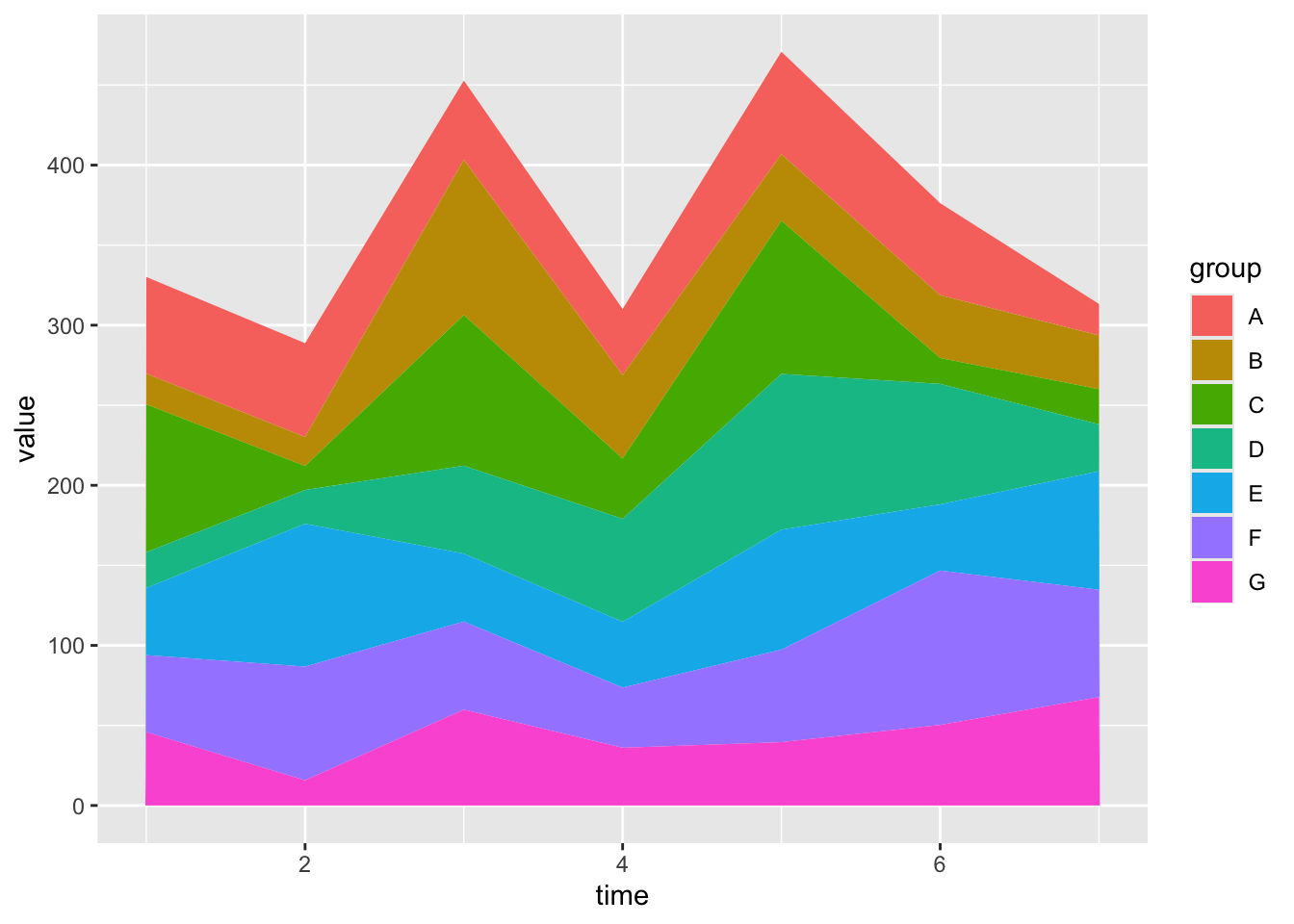
# 给定特定顺序:将 group 列转换为因子,并指定分组顺序
data$group <- factor(data$group, levels = c("B", "A", "D", "E", "G", "F", "C"))
# 再次绘制面积图,分组顺序按照上面指定的 levels
ggplot(data, aes(x = time, y = value, fill = group)) +
geom_area() +
theme(legend.position = "bottom") # 将图例放在底部, 为了排版
# 也可以按字母顺序排序分组
myLevels <- levels(data$group) # 获取当前分组的 levels
data$group <- factor(data$group, levels = sort(myLevels)) # 按字母顺序排序
ggplot(data, aes(x = time, y = value, fill = group)) +
geom_area() +
theme(legend.position = "bottom") # 将图例放在底部, 为了排版
# 按某一时间点(如 time = 6)对应的 value 值进行排序
myLevels <- data |>
dplyr::filter(time == 6) |> # 过滤出 time 等于 6 的数据
dplyr::arrange(value) # 按 value 升序排列
data$group <- factor(data$group, levels = myLevels$group) # 按 value 排序后的分组顺序设置因子 levels
ggplot(data, aes(x = time, y = value, fill = group)) +
geom_area() +
theme(legend.position = "bottom") # 将图例放在底部, 为了排版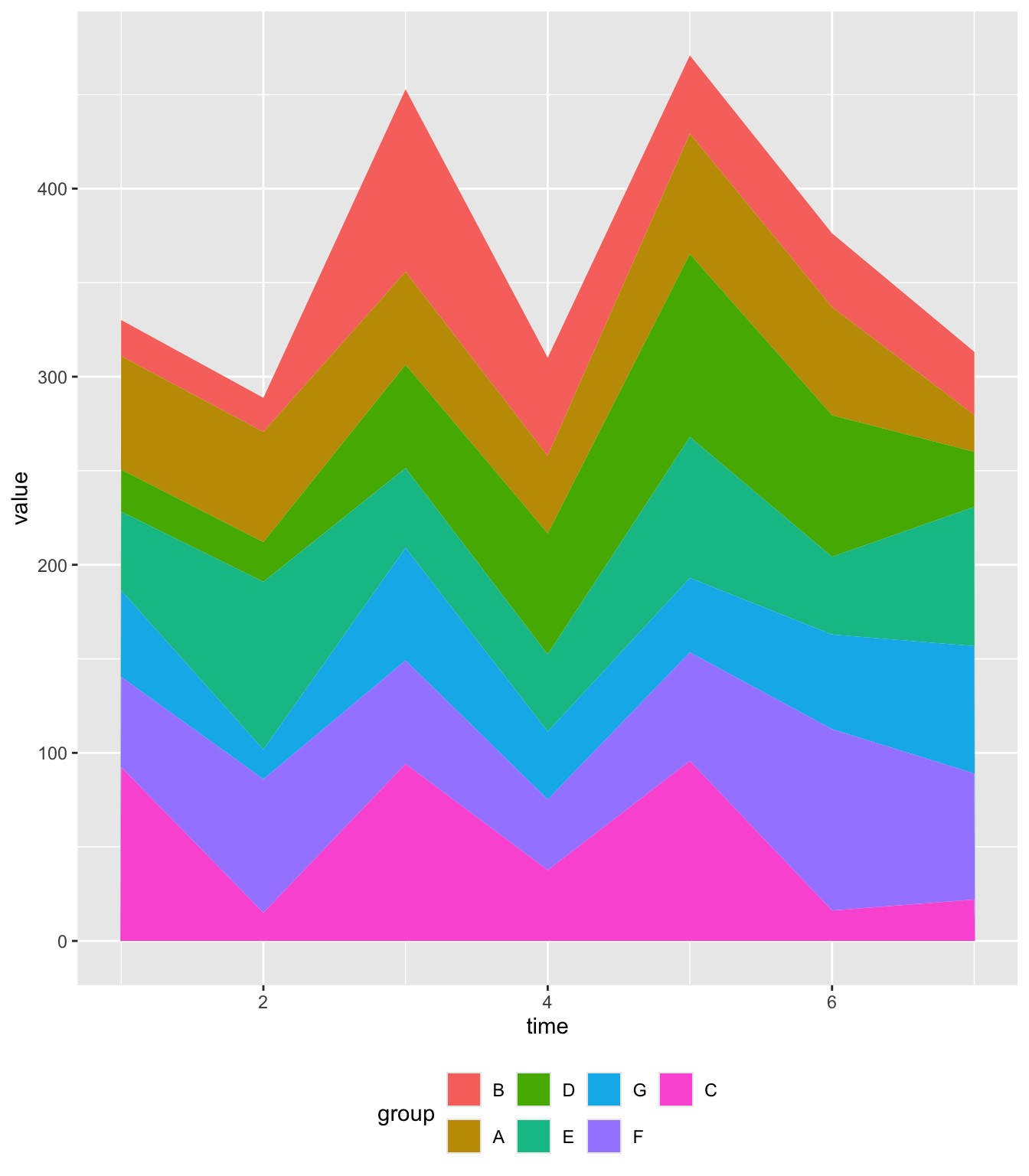
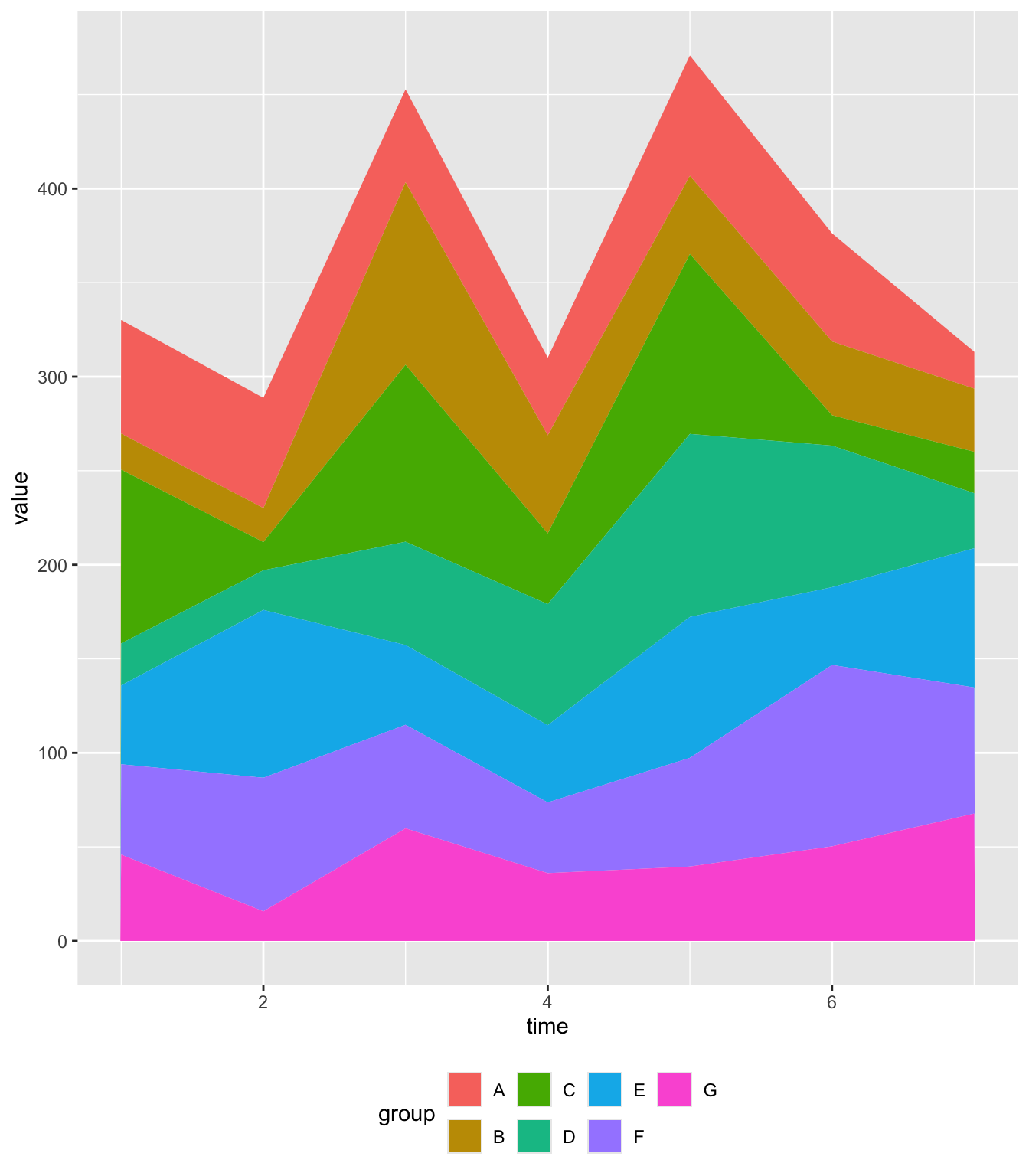
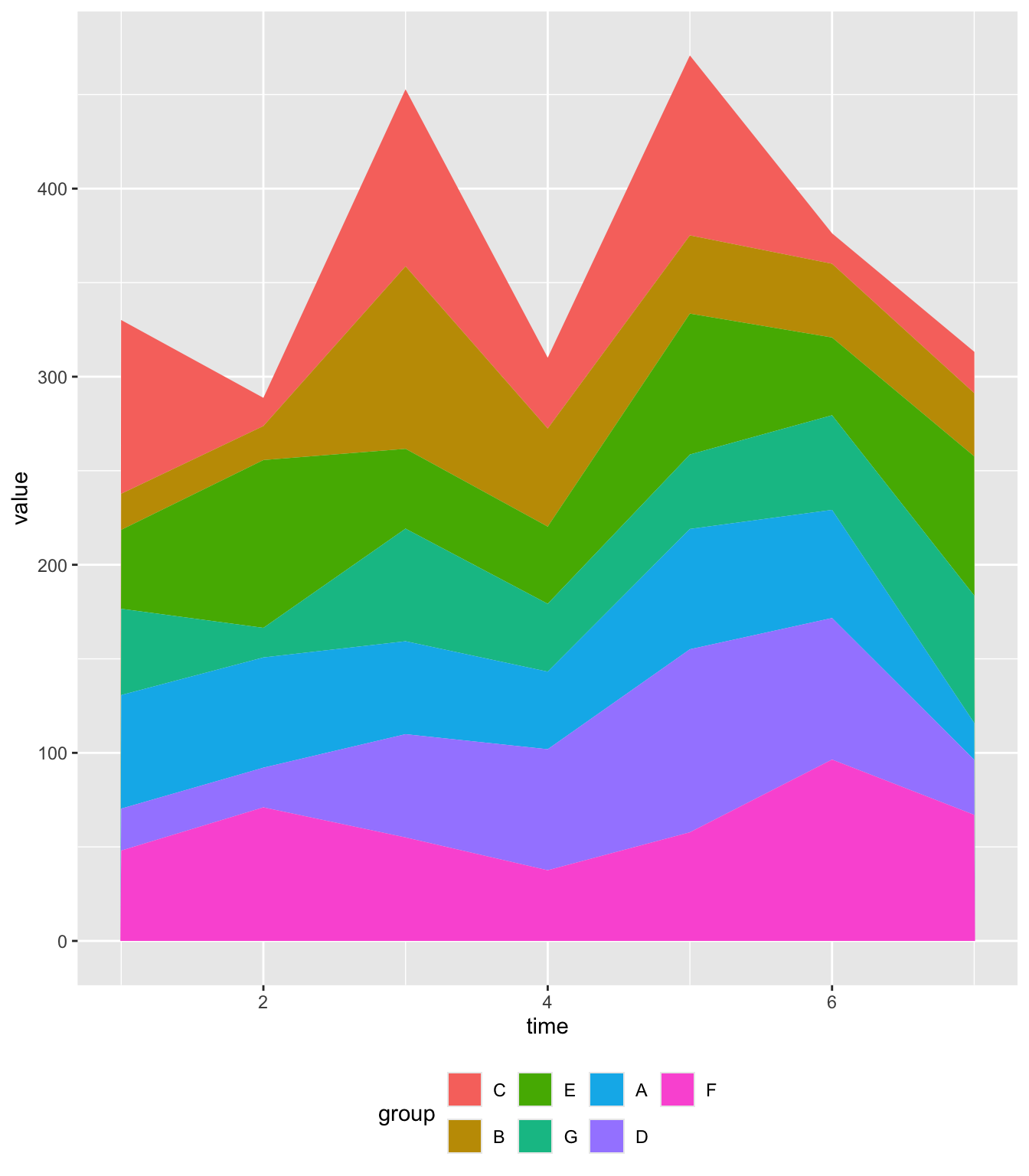
控制堆叠面积图的分组顺序,并演示如何按指定顺序、字母顺序和特定时间点的数值排序
比例堆叠面积图(每组的总和都是100):
library(dplyr)
# 按 time 和 group 分组,计算每组的 value 总和,并计算每组所占比例
data <- data |>
group_by(time, group) |> # 按时间和分组分组
summarise(n = sum(value)) |> # 计算每组的 value 总和,命名为 n
mutate(percentage = n / sum(n)) # 计算每组所占比例
# # 注意:如果不用 dplyr 也可以这样计算百分比
# my_fun <- function(vec){
# as.numeric(vec[2]) / sum(data$value[data$time == vec[1]]) * 100 # 计算每一行 value 占该时间点总和的百分比
# }
# data$percentage <- apply(data, 1, my_fun) # 对每一行应用函数,得到百分比
# 绘制比例堆叠面积图
ggplot(data, aes(x = time, y = percentage, fill = group)) +
geom_area(alpha = 0.6, size = 1, colour = "black") # 绘制面积图,设置透明度、线宽和边框颜色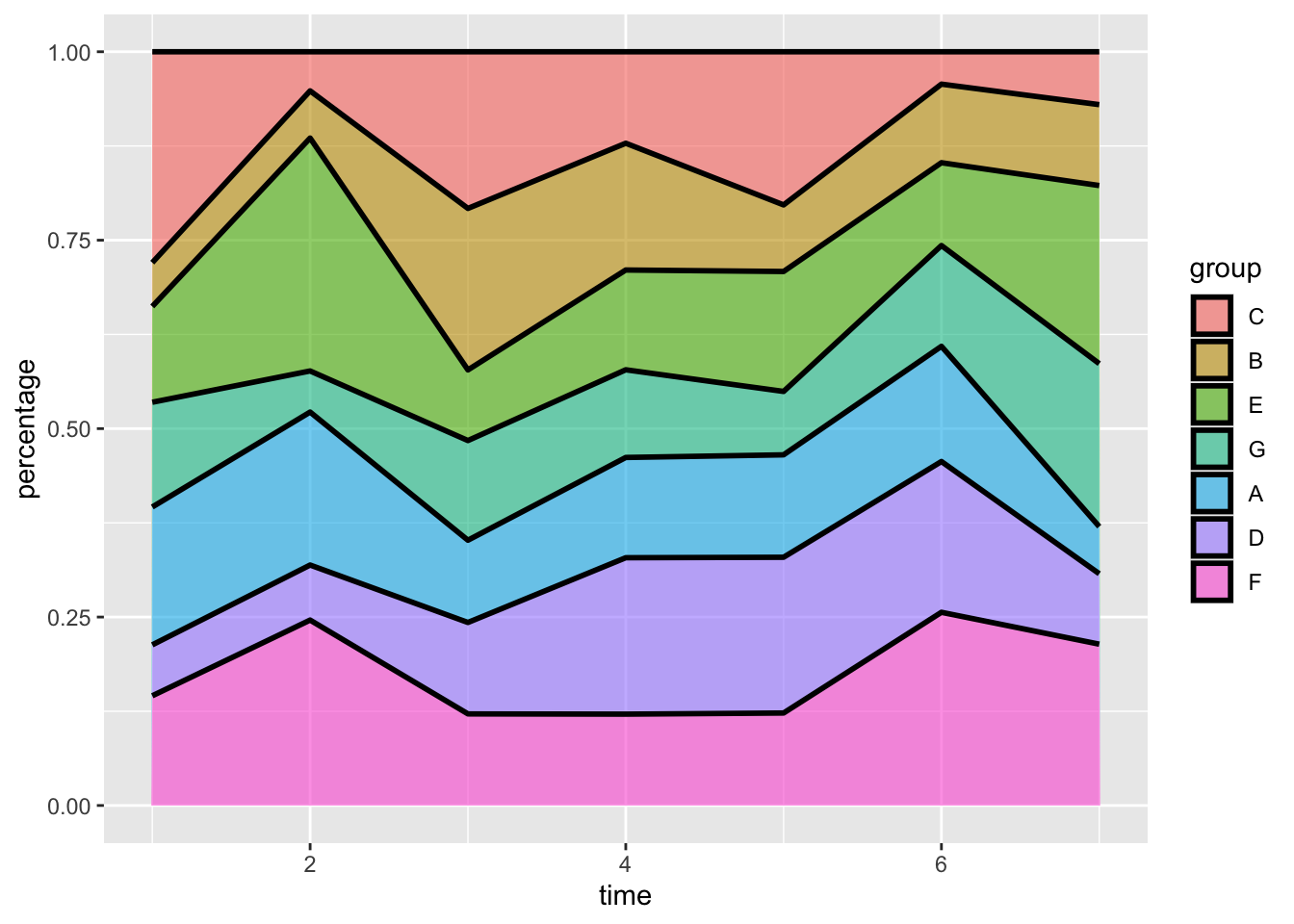
再更改一下颜色和样式:
# 加载所需包
library(viridis) # 提供高可读性的配色方案
library(hrbrthemes) # 提供美观的 ggplot2 主题
# 绘制堆叠面积图
ggplot(data, aes(x = time, y = value, fill = group)) + # 指定数据和映射关系,fill 按 group 分组
geom_area(alpha = 0.6, size = .5, colour = "white") + # 绘制面积,设置透明度、边框宽度和颜色
scale_fill_viridis(discrete = TRUE) + # 使用 viridis 离散色板填充
theme_ipsum() + # 应用 hrbrthemes 主题
ggtitle("The race between ...") # 添加标题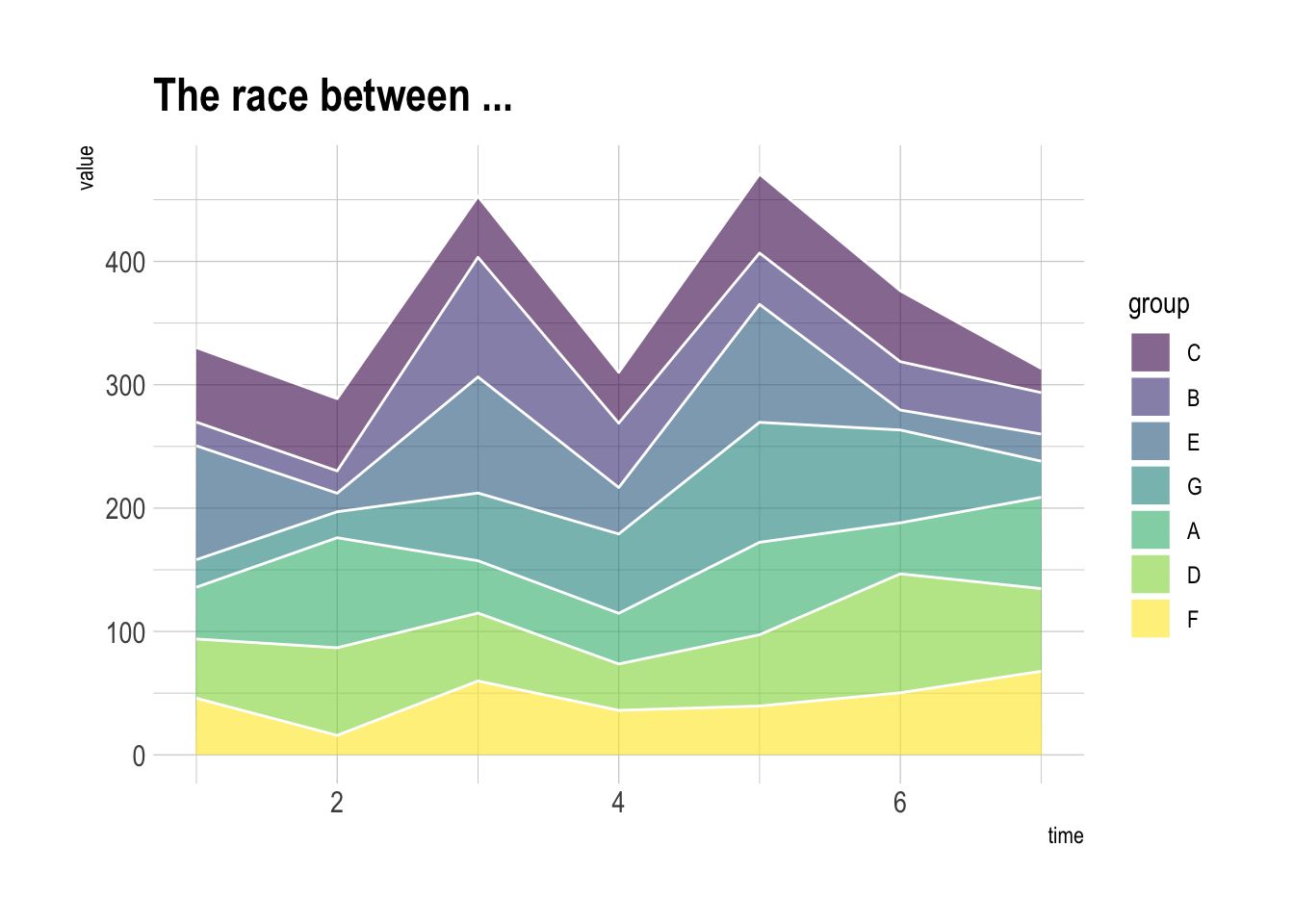
ggplotly()library(ggplot2) # ggplot2 包用于绘图
library(dplyr) # dplyr 包用于数据处理
library(babynames) # babynames 数据集
library(viridis) # viridis 包用于配色
library(hrbrthemes) # hrbrthemes 包用于美化主题
library(plotly) # plotly 包用于交互式图形
# 从 babynames 数据集中筛选指定的女性名字
data <- babynames |>
filter(name %in% c("Ashley", "Amanda", "Jessica", "Patricia", "Linda", "Deborah", "Dorothy", "Betty", "Helen")) |> # 只保留指定名字
filter(sex == "F") # 只保留女性数据
# 使用 ggplot2 绘制堆叠面积图
p <- data |>
ggplot(aes(x = year, y = n, fill = name, text = name)) + # year 为 x 轴,n 为 y 轴,按 name 填充,text 用于交互显示
geom_area() + # 绘制面积图
scale_fill_viridis(discrete = TRUE) + # 使用 viridis 离散色板
theme(legend.position = "none") + # 不显示图例
ggtitle("Popularity of American names in the previous 30 years") + # 添加标题
theme_ipsum() + # 应用 hrbrthemes 主题
theme(legend.position = "none") # 再次确保图例不显示
# 使用 plotly 将静态图转换为交互式图形
p <- ggplotly(p, tooltip = "text") # tooltip 显示名字
p # 输出交互式图形使用 plotly 实现交互式堆叠面积图,展示美国女性常见名字随时间的流行趋势
dygraph()
# 加载所需的 R 包
library(dygraphs) # dygraphs 包用于交互式时间序列可视化
library(xts) # xts 包用于数据框与 xts 格式转换
library(tidyverse) # tidyverse 包用于数据处理
library(lubridate) # lubridate 包用于处理日期和时间
# 读取数据
path <- "https://raw.githubusercontent.com/holtzy/R-graph-gallery/master/DATA/bike.csv"
data <- read.table(path, header = TRUE, sep = ",") |> head(300) # 读取前 300 行数据
# 检查变量类型(可选)
# str(data)
# 将 datetime 列从因子类型转换为日期时间格式
data$datetime <- ymd_hms(data$datetime)
# 创建 xts 对象,dygraphs 需要 xts 格式的数据
don <- xts(x = data$count, order.by = data$datetime)
# 绘制交互式面积图
p <- dygraph(don) |>
dyOptions(
labelsUTC = TRUE, # 使用 UTC 时间标签
fillGraph = TRUE, # 填充面积
fillAlpha = 0.1, # 填充透明度
drawGrid = FALSE, # 不显示网格线
colors = "#D8AE5A" # 设置线条颜色
) |>
dyRangeSelector() |> # 添加范围选择器
dyCrosshair(direction = "vertical") |> # 添加垂直十字准线
dyHighlight(
highlightCircleSize = 5, # 高亮时圆圈大小
highlightSeriesBackgroundAlpha = 0.2, # 高亮系列背景透明度
hideOnMouseOut = FALSE # 鼠标移出时不隐藏高亮
) |>
dyRoller(rollPeriod = 1) # 添加滚动平均选择器,默认窗口为 1
p使用 dygraphs 包绘制交互式面积图
Base R# 创建数据框,x 从 1 到 10,y 为 1 到 15 的随机排列
data <- data.frame(x = seq(1, 10), y = sample(seq(1, 15), 10))
# 先绘制折线图,type="o" 表示点和线都画,lwd=3 线宽,pch=20 实心圆点
plot(
data,
col = rgb(0.2, 0.1, 0.5, 0.9), # 设置颜色为半透明深紫色
type = "o", # o 表示点和线都画
lwd = 3, # 线宽为3
xlab = "", # 不显示x轴标题
ylab = "size", # y轴标题为 size
pch = 20 # 点的形状为实心圆
)
# 用 polygon 填充面积
# c(min(data$x), data$x, max(data$x)):x 轴从最小值到最大值,首尾闭合
# c(min(data$y), data$y, min(data$y)):y 轴从最小值到最大值,首尾闭合
polygon(
c(min(data$x), data$x, max(data$x)), # x 坐标,首尾闭合
c(min(data$y), data$y, min(data$y)), # y 坐标,首尾闭合
col = rgb(0.2, 0.1, 0.5, 0.2), # 填充为更透明的紫色
border = FALSE # 不显示边框
)